morishitaです。
Vue.Draggableをネストさせて利用してみたので紹介します。
Vue.Draggable とは
Vue.Draggable はVueアプリケーションでドラッグドロップ操作を実現するのにとても便利なコンポーネントライブラリです。
単に編集対象のリストを表示して、それをドラッグドロップで並べ替えるだけだととても簡単に実装できます。
複数のリスト間で要素を移動したり、階層的なリストの並べ替えもできたりとちょっと複雑な要件にも対応できる柔軟な作りになっています。
言葉で説明するより動いているものに触っているみのが早いのでライブデモのページを参照してみてください。
sortablejs.github.io
いこレポでは Vue.Draggable をコンテンツ管理機能(CMS)で利用しています。
report.iko-yo.net
いこレポのCMSとその課題
いこレポは独自のCMSを開発しており、それを使って編集チームの皆さんが記事を制作しています。
記事本文は見出し、テキスト、画像などのブロックと呼んでいる単位で登録して構成します。
本文編集のUIはこんな感じです。
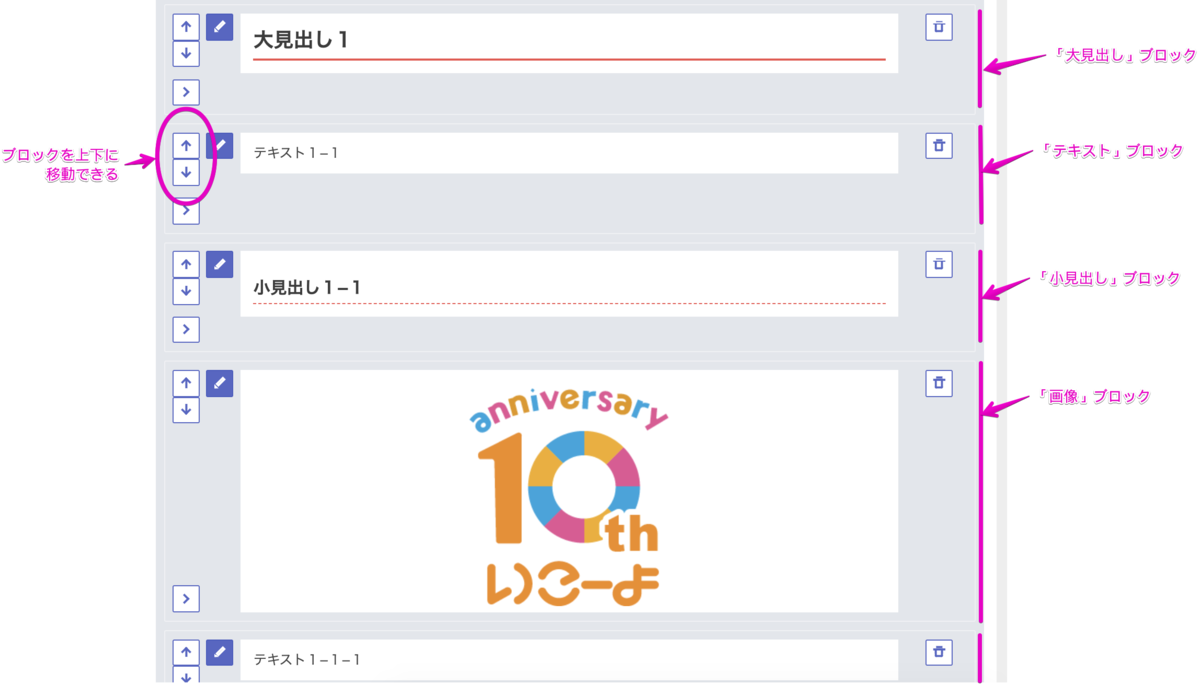 いこレポのCMS
いこレポのCMS
記事を一通り書き終えてから、より読みやすくわかりやすいようにブロックを並べ替えて並べかえるそうなのですが、効率よく編集するために複数のブロックをまとめて移動したいという改善要望をもらっていました。(ちなみにブロック1つづつなら移動する機能は以前から持っています。)
しかし詳しくヒアリングしてみると単に複数のブロックということではなく一体として意味を持つブロックの塊、つまり段落(セクション)を移動したいということでした。そこで次のように見出しアウトラインとして表示してドラッグドロップで順序を入れ替えることができるアウトライン編集機能を提案して実装することにしました。
 アウトライン編集
アウトライン編集
いこレポの記事本文データの構造
いこレポではJSONで本文データを保持しています。
見出しや、テキストなどを前述したようにブロックと呼んでおり、そのリストを本文として次のようなJSON形式でデータ保持しています。
[
{"type":"text", "html":"リード1", "blockId":"bid-0"},
{"type":"text", "html":"リード2", "blockId":"bid-1"},
{"type":"headline_2", "html":"大見出し1", "url":"", "blockId":"bid-2"},
{"type":"text", "html":"テキスト1−1", "blockId":"bid-3"},
{"type":"headline_3", "html":"小見出し1−1", "blockId":"bid-4"},
{"type":"image", "url":"/image.png", "blockId":"bid-5"},
{"type":"text", "html":"テキスト1−1−1", "blockId":"bid-6"},
{"type":"headline_3", "html":"小見出し1−3", "blockId":"bid-7"},
{"type":"text", "html":"テキスト1−3−1", "blockId":"bid-8"},
{"type":"text", "html":"テキスト1−3−2", "blockId":"bid-9"},
{"type":"headline_3", "html":"小見出し1−2", "blockId":"bid-10"},
{"type":"text", "html":"テキスト1−2−1", "blockId":"bid-11"},
{"type":"headline_2", "html":"大見出し2", "url":"", "blockId":"bid-12"},
{"type":"text", "html":"テキスト2−1", "blockId":"bid-13"},
{"type":"headline_3", "html":"小見出し2−1", "blockId":"bid-14"},
{"type":"text", "html":"テキスト2−1−1", "blockId":"bid-15"},
{"type":"text", "html":"テキスト2−1−2", "blockId":"bid-16"},
{"type":"headline_3", "html":"小見出し2−2", "blockId":"bid-17"},
{"type":"text", "html":"テキスト2−2−1", "blockId":"bid-18"},
{"type":"text", "html":"テキスト2−2−2", "blockId":"bid-19"},
{"type":"headline_3", "html":"小見出し2−3", "blockId":"bid-20"},
{"type":"text", "html":"テキスト2−3−1", "blockId":"bid-21"},
{"type":"text", "html":"テキスト2−3−2", "blockId":"bid-22"},
{"type":"headline_2", "html":"大見出し3", "url":"", "blockId":"bid-23"},
{"type":"text", "html":"テキスト3−1", "blockId":"bid-24"},
{"type":"headline_3", "html":"小見出し3−1", "blockId":"bid-25"},
{"type":"text", "html":"テキスト3−1−1", "blockId":"bid-26"},
{"type":"text", "html":"テキスト3−1−2", "blockId":"bid-27"}
]
"type":"headline_2"が大見出し、"type":"headline_3"が小見出して、"type":"text"が本文テキスト、"type":"image"が画像を表します。
各ブロックのblockIdは一意IDとなっています。
見ての通り、データ構造的にはフラットなブロックのリストとなっており、段落という概念はデータ構造上はありません。
文章構造上は次の条件でグルーピングされる一連のブロックがセクション(段落)となります。
"type":"headline_2"ブロックから次の"type":"headline_2"まで"type":"headline_3"から次の"type":"headline_2"あるいは"type":"headline_3"まで
図示するとこんな感じです。
 セクション構造
セクション構造
各セクションの見出しとなる"type":"headline_2"、"type":"headline_3"のブロックを抽出して、次のようなアウトラインデータを作ります。
[
{"type":"headline_2", "html":"大見出し1", "blockId":"bid-2",
"h3":[{"type":"headline_3", "html":"小見出し1−1", "blockId":"bid-4"},
{"type":"headline_3", "html":"小見出し1−2", "blockId":"bid-6"},
{"type":"headline_3", "html":"小見出し1−3", "blockId":"bid-8"}]},
{"type":"headline_2", "html":"大見出し2", "blockId":"bid-11",
"h3":[{"type":"headline_3", "html":"小見出し2−1", "blockId":"bid-13"},
{"type":"headline_3", "html":"小見出し2−2", "blockId":"bid-16"},
{"type":"headline_3", "html":"小見出し2−3", "blockId":"bid-19"}]},
{"type":"headline_2", "html":"大見出し3", "blockId":"bid-22",
"h3":[{"type":"headline_3", "html":"小見出し3−1", "blockId":"bid-24"}]}
]
このJSONを次のテンプレートでレンダリングして、上のGIFアニメーションで示したアウトラインのUIを作っています。
<template lang="pug">
div.outline-editor
draggable(:list="outline" tag="ul" :group="{ name: 'outline' }" :move="onMove" @end="end")
li(v-for="item in outline" :class="item.type" :key="item.blockId" :value="item", :data-block-id="item.blockId") {{item.html}} {{item.blockId}}
draggable(:list="item.h3" tag="ul" :group="{ name: 'outline' }" :move="onMove" @end="end")
li(v-for="h3 in item.h3" :class="h3.type" :value="h3" :data-block-id="h3.blockId") {{h3.html}} {{h3.blockId}}
</template>
見ての通り、draggableをネストさせて使っています。
これにより次の操作を実現しています。
"type":"headline_2"をドラッグしたときには子の"type":"headline_3"も一緒に移動する"type":"headline_3"をドラッグすると"type":"headline_3"だけが移動する
単純な Vue.Draggable の利用と異なる部分は次の点です。
- リスト(アウトライン)がネストしているが、階層を超えてブロックを移動したい
- 操作するリスト(アウトライン)を並べ替えたいのではなく、本文を並べ替えたい
階層を超えたブロックの移動
上記に示したアウトラインデータでは次の合計4つのリストができます。
"type":"headline_2"を要素に持つリスト"type":"headline_2" のそれぞれにネストした "type":"headline_3" を要素とする3つのリスト
Vue.Draggableではリストごとに並べ替えができ、異なるリスト間は移動できません。
しかしgroup属性を使えば、リスト間の移動を実現できます。
上記のテンプレートのコードでは:group="{ name: 'outline' }"をすべてのdraggableで同じ値で指定しています。同じgroupのリストは1つのリストして扱われます。これによりすべてのdraggableが同一リストとなり、ドラッグしたセクションをアウトラインのどこにでもドロップできるようになります。つまり、"type":"headline_3"セクションを別の"type":"headline_2"セクションに移動するという操作が実現できます。
操作するリスト(アウトライン)を並べ替えたいのではなく、本文を並べ替えたい
なんのこっちゃと思われるかもしれませんが、単純な Vue.Draggable の利用では、UIに表示されて操作するリストが並べ替えたい対象です。ドラックして変更すると、コンポーネントに渡したリストデータも変更さるのでそれをVuexストアに反映したり、サーバにPOSTして永続保存するなりすれば良いです。
今回はそうではなく、アウトラインを操作して本文のブロックを並べ替えたいのです。
操作対象のリストと最終的に変更したいリストが異なるということです。
そのために、アウトラインからは次の2つを取得し、これらの値から本文データを並べ替えることを考えました。
さて、これらをどうやって取得するかですが、最初はドラッグしたブロックをドロップした時に発生するendイベントで取れると思って渡されるイベントオブジェクトを色々いじってみたのですが、取りづらい。それでいろいろ試行錯誤して最終的にmove属性にコールバック関数を渡して得られるonMoveイベントからのほうが取りやすかったのでそちらから次のように取りました。
- 移動したブロック:
onMove.dragged
- ドロップした位置にあるブロック:
onMove.related
移動先の位置相当のものとして ドロップした位置にあるブロック を取得します。
各ブロックには一意なblockIdつけてあるので、ちょっと泥臭いですが、本文のブロックのリストを走査して移動したブロックを先頭の見出しとするセクションと移動先のインデックスを求めました。
後は、本文ブロックリストから一旦セクションに属するブロック群を抜き取って移動先に挿入する操作を行いセクションの移動が完了です。
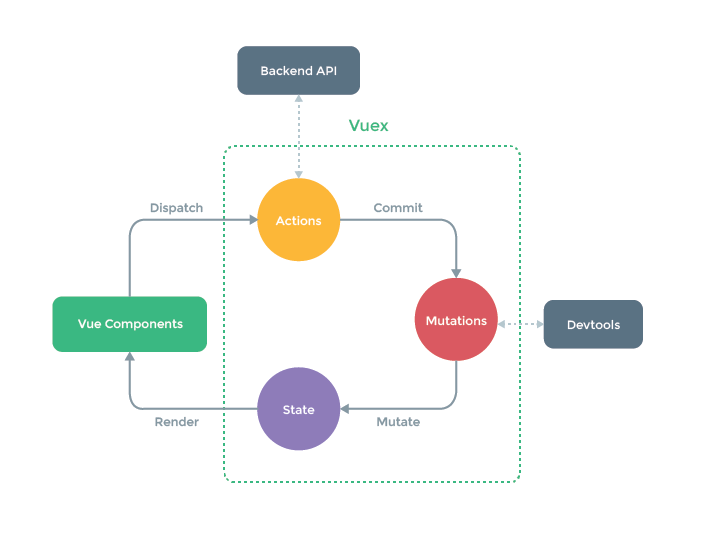
アウトライン上で並べ替え操作をすると、Vuexストアに格納している本文データを更新します。するとVue+Vuexの単方向データフローでアウトラインの表示も更新するという仕組みです。
こうして上のGIFアニメのようなアウトライン編集機能を実現しました。
まとめ
- Vue.Draggable ではネストしたリストの並べ替えも簡単
- 操作するリストと、変更したいリストが異なる場合にはちょっと面倒
- ドロップ先要素の上下どちらに挿入するのかがわからない(未解決課題)
実は、移動先はドロップする位置にある要素はすぐ取れるのですが、その要素の上下どちらに挿入するのかを知る方法を見いだせませんでした。
今回は諦めて、ドロップ要素の前に挿入することにしています。そのためアウトラインの末尾に移動できません。末尾の要素にドロップするとその前に移動するので、末尾要素を移動すると目的の移動は実現できますが、ちょっと面倒です。今後の課題です。
最後に
アクトインディではエンジニアを募集しています。
actindi.net