morishitaです。
以前、弊社のWebエンジニアキエンが次のエントリで紹介した prontoによる自動レビューですが、今ではほかのRailsアプリケーションにも導入して使っています。
うっかりしたコードを書くと容赦のない指摘コメントが付きます。
その多くはコードフォーマットに関するものなのですが、時々rubocop-performanceにより「遅いかもしれないので書き直しましょう」という指摘をされます。
へーそうなのかーと素直に修正してきたのですが、ツールを活用するのはいいのだけど、盲従するのは良くないぁと心に引っかかるものを感じていました。
JuanitoFatas/fast-rubyにも測定結果があるのですが、ざっと見て古すぎるRubyバージョン(2.2など)での結果が更新されていないものが結構あるなぁと思いました。
また、Rubyのバージョンによる差も見てみたかったので、今回、自分で確認してみました。
Rubocop Performance とは
Rubocopのプラグインで性能低下につながるコードを指摘し修正を促す Cop の集合です。
最近、Rubocop本体から分離され rubocop-hq/rubocop-performanceでリポジトリが公開されています。
Rubocop Performanceには次の Cop が含まれています。
- Performance/Caller
- Performance/CaseWhenSplat
- Performance/Casecmp
- Performance/ChainArrayAllocation
- Performance/CompareWithBlock
- Performance/Count
- Performance/Detect
- Performance/DoubleStartEndWith
- Performance/EndWith
- Performance/FixedSize
- Performance/FlatMap
- Performance/InefficientHashSearch
- Performance/OpenStruct
- Performance/RangeInclude
- Performance/RedundantBlockCall
- Performance/RedundantMatch
- Performance/RedundantMerge
- Performance/RegexpMatch
- Performance/ReverseEach
- Performance/Size
- Performance/StartWith
- Performance/StringReplacement
- Performance/TimesMap
- Performance/UnfreezeString
- Performance/UriDefaultParser
もっとたくさんあるかと思っていたのですが、25個なんですね。
計測について
計測には BenchmarkDriver を利用しました。
Rubocopのドキュメントに bad と good の例が掲載されていますが、基本的にはそれをBenchmarkDriverで計測してみて比較しました。
例をなるべく変更せずに計測する方針で行いましたが、文字列、配列、ハッシュなどは定数にして使い回すようにしています。
各 Cop が論点にしているポイントだけをなるべく計測するため、これらの生成コストを計測に含めないようにするためです。
計測に利用したコードはこのエントリにも掲載しますが、次のリポジトリにも置いておきます。
rubocop-performance-measurements
単に bad と good を計測するだけでなく複数のRubyのバージョンで計測しています。
一応、Rubocopはまだ、Ruby 2.3 をサポートしているようなので、
それ以降のバージョンということで次のRubyバージョンで計測しました。
- 2.3.8
- 2.4.6
- 2.5.4
- 2.6.3
- 2.7.0-preview1
一部、Ruby 2.3.8 では実装されていないメソッドに関する Cop では 2.3.8 を除外して計測しました。
結果は秒あたりの実行回数 ips (Iteration per second = i/s)で示します。
各結果ともbenchmark_driver-output-gruffによるグラフで示しますが、グラフが長いほうが高速ということです。
また、結果の値自体は計測環境の性能により変わります。 なので、サンプル間の差に着目してください。
では順に見ていきます。
1. Performance/Caller
メソッドの呼び出し元を取得するために caller[n] より、caller(n..n).firstを使おうという Cop ですね。
次のコードで計測しました。
# rubocop-performance Performance/Caller require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def bad_sample1 caller[1] end def bad_sample2 caller.first end def bad_sample3 caller_locations.first end def good_sample1 caller(1..1).first end def good_sample2 caller_locations(1..1).first end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ good_sample1 } x.report %{ good_sample2 } end
上記コードの実行結果は次のとおりです。

結果からはどちらでも差がないように思われます。
callerよりcaller_locationsを使ったほうが良さそうということはわかるのですが、
caller(n..n).first の性能的優位性は感じられません。
こんな小さなコードではなく、Railsの中などで使うとメソッドの呼び出し階層が深くなるので効果が出てくるのでしょうか。
2. Performance/CaseWhenSplat
case の when に splat展開(配列展開。 例:*array)を含むものを後ろに持ってきたほうがパフォーマンスが向上する可能性があるという Cop ですね。
次のコードで計測しました。
# rubocop-performance Performance/CaseWhenSplat require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY BAR = 2 BAZ = 3 FOOBAR = 4 CONDITION = [1, 2, 3, 4] def bad_sample1 foo = BAZ case foo when *CONDITION BAR when BAZ FOOBAR end end def bad_sample2 foo = 5 case foo when *[1, 2, 3, 4] BAR when 5 FOOBAR end end def good_sample1 foo = BAZ case foo when BAZ FOOBAR when *CONDITION BAR end end def good_sample2 foo = 5 case foo when 1, 2, 3, 4 BAR when 5 BAZ end end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ good_sample1 } x.report %{ good_sample2 } end
結果は次のとおりです。

good_sample のほうがパフォーマンスがいいです。
whenは上から評価されます。なのでsplat展開する条件以外にヒットするケースが多い場合にはsplat展開する条件を後ろに置くことで、splat展開の回数が減り、その分コストが少ないということだと思います。
bad_sample1の結果を見るとruby2.6以降はsplat展開の性能もずいぶん上がっているのだなとわかりますね。
3. Performance/Casecmp
大文字、小文字関係なく文字列の一致を判定するにはcasecompメソッドを使いましょうというCopです。
次のコードで計測しました。
# rubocop-performance Performance/Casecmp require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY STR_U = 'ABC' STR_L = 'abc' def bad_sample1 STR_U.downcase == STR_L end def bad_sample2 STR_L.upcase.eql? STR_U end def bad_sample3 STR_L == STR_U.downcase end def bad_sample4 STR_U.eql? STR_L.upcase end def bad_sample5 STR_U.downcase == STR_U.downcase end def good_sample1 STR_L.casecmp(STR_U).zero? end def good_sample2 STR_U.casecmp(STR_L).zero? end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ bad_sample4 } x.report %{ bad_sample5 } x.report %{ good_sample1 } x.report %{ good_sample2 } end
結果は次のとおりです。

good_sample のほうが速いですね。
'ABC'.downcase == 'abc' みたいなコードは書きがちですが、改めたほうが良さそうです。
4. Performance/ChainArrayAllocation
Arrayのメソッドcompact, flatten, mapなどはメソッドチェインして使いがちです。
しかし、その都度中間状態の配列が生成されるのでcompact!, flatten!, map!で元の配列を書き換えたほうが速いよという Cop です。
# rubocop-performance Performance/ChainArrayAllocation require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def bad_sample array = ["a", "b", "c"] array.compact.flatten.map { |x| x.downcase } end def good_sample array = ["a", "b", "c"] array.compact! array.flatten! array.map! { |x| x.downcase } array end RUBY x.report %{ bad_sample } x.report %{ good_sample } end
結果は次のとおりです。

もっと差がつくかと思ったのですが、それほどでもないです。
もっと大きな配列なら差が広がるかもしれないですが、メソッドチェーンのほうがコードがスッキリし、読みやすい場合も多いので配列が大きくなくて、ループの中でないなら気にするほどでは無いかと思います。
5. Performance/CompareWithBlock
オブジェクトやハッシュの属性値でsort、min、maxで比較するときに、比較する条件をブロックで渡すよりも、sort_by、min_by、max_byを使おうという Cop です。
次のコードで計測しました。
# rubocop-performance Performance/CompareWithBlock require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY class Elm attr_accessor :foo def initialize(foo) @foo = foo end end ARRAY = [Elm.new(5), Elm.new(4), Elm.new(3), Elm.new(2), Elm.new(1)] HASH_ARRAY = [{ foo: 5 }, { foo: 4 }, { foo: 3 }, { foo: 2 }, { foo: 1 }] def bad_sample_sort1 ARRAY.sort { |a, b| a.foo <=> b.foo } end def bad_sample_max ARRAY.max { |a, b| a.foo <=> b.foo } end def bad_sample_min ARRAY.min { |a, b| a.foo <=> b.foo } end def bad_sample_sort_hash HASH_ARRAY.sort { |a, b| a[:foo] <=> b[:foo] } end def good_sample_sort1 ARRAY.sort_by(&:foo) end def good_sample_sort2 ARRAY.sort_by { |v| v.foo } end def good_sample_sort3 ARRAY.sort_by do |var| var.foo end end def good_sample_max ARRAY.max_by(&:foo) end def good_sample_min ARRAY.min_by(&:foo) end def good_sample_sort_hash HASH_ARRAY.sort_by { |a| a[:foo] } end RUBY x.report %{ bad_sample_sort1 } x.report %{ good_sample_sort1 } x.report %{ good_sample_sort2 } x.report %{ good_sample_sort3 } x.report %{ bad_sample_max } x.report %{ good_sample_max } x.report %{ bad_sample_min } x.report %{ good_sample_min } x.report %{ bad_sample_sort_hash } x.report %{ good_sample_sort_hash } end
結果は次のとおりです。

うーん、どのRubyのバージョンでも bad_sample のほうがパフォーマンス良さそうですね。 計測の仕方が良くないのかなぁ。
6. Performance/Count
配列の要素数を数える場合に、すべての要素ではなく条件に一致するものだけ数えたい場合があります。
Array#selectなどで数えたい要素だけに絞り込んでからcountするよりも、Array#count に数える条件を与えるほうが良いという Cop です。
計測に使ったコードは次のとおりです。
ActiveRecordに関する例がドキュメントにはあるのですが、それは含めていません。
# rubocop-performance Performance/Count require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY class Elm attr_accessor :value def initialize(value) @value = value end end NUM_ARRAY = [1, 2, 3] OBJ_ARRAY = [Elm.new(5), Elm.new(4), Elm.new(3), Elm.new(2), Elm.new(5)] def bad_sample1 NUM_ARRAY.select { |e| e > 2 }.size end def bad_sample2 NUM_ARRAY.reject { |e| e > 2 }.size end def bad_sample3 NUM_ARRAY.select { |e| e > 2 }.length end def bad_sample4 NUM_ARRAY.reject { |e| e > 2 }.length end def bad_sample5 NUM_ARRAY.select { |e| e > 2 }.count { |e| e.odd? } end def bad_sample6 NUM_ARRAY.reject { |e| e > 2 }.count { |e| e.even? } end def bad_sample7 OBJ_ARRAY.select(&:value).count end def good_sample1 NUM_ARRAY.count { |e| e > 2 } end def good_sample2 NUM_ARRAY.count { |e| e < 2 } end def good_sample3 NUM_ARRAY.count { |e| e > 2 && e.odd? } end def good_sample4 NUM_ARRAY.count { |e| e < 2 && e.even? } end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ bad_sample4 } x.report %{ bad_sample5 } x.report %{ bad_sample6 } x.report %{ bad_sample7 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } x.report %{ good_sample4 } end
計測結果は次のとおりです。

good_sampleのほうが総じて結果が良いですね。
その差はあんまり大きくありませんが、配列が大きくなると顕著に差が広がるかもしれません。コードも短くなるのでRubocopに従ったほうがいいかと思います。
コードの簡潔さという点でも、Array#select{}.size よりも Array#count{} の方がスッキリしていていいと思います。
7. Performance/Detect
配列の中から条件に一致する最初の要素や最後の要素を取り出す場合には select と first や last を組み合わせるよりdetectメソッドを使いましょうという Cop です。
detectメソッドは、find の別名なので find を使ってもいいです。
計測コードは次のとおりです。
# rubocop-performance Performance/Detect require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY ARRAY = [1, 1, 0, 1, 0, 1, 0, 1 ,0 ,1] def bad_sample1 ARRAY.select { |item| item > 0 }.first end def bad_sample2 ARRAY.select { |item| item > 0 }.last end def bad_sample3 ARRAY.find_all { |item| item > 0 }.first end def bad_sample4 ARRAY.find_all { |item| item > 0 }.last end def good_sample1 ARRAY.detect { |item| item > 0 } end def good_sample2 ARRAY.reverse.detect { |item| item > 0 } end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ bad_sample4 } x.report %{ good_sample1 } x.report %{ good_sample2 } end
計測結果は次のとおりです。

good_sample1 の優位性がはっきりしていますねRubocopの指摘に従ったほうが良さそうです。
good_sample2はそれほどパフォーマンスよくないです。reverseメソッドの性能がイマイチなのでしょうか。
StartWith/EndWith
String#start_with? と String#end_with? に関する Cop は次の3つあります。
3つ合わせて見ていきます。
8. Performance/DoubleStartEndWith
まずは、Performance/DoubleStartEndWith。
例えばaまたはbで始まるかどうかを判定しないのなら、start_with? を || でつないで2回使うのではなく start_with? に2つ引数を渡したほうが速いという Cop です。
計測に使ったコードは次のとおりです。
# rubocop-performance Performance/DoubleStartEndWith require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY module Some CONST = 'c' end STR = 'hogehoge' VAR1 = 'a' VAR2 = 'b' def bad_sample1 STR.start_with?('a') || STR.start_with?(Some::CONST) end def bad_sample2 STR.start_with?('a', 'b') || STR.start_with?('c') end def bad_sample3 STR.end_with?(VAR1) || STR.end_with?(VAR2) end def good_sample1 STR.start_with?('a', Some::CONST) end def good_sample2 STR.start_with?('a', 'b', 'c') end def good_sample3 STR.end_with?(VAR1, VAR2) end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } end
結果は次のとおりです。

good_sampleのほうがパフォーマンスいいですね。
String#start_with? と String#end_with?って複数の引数を取れるんですね。速いしコードがスッキリするのでいいですね。
9. Performance/EndWith
続いてString#end_with?です。
正規表現で文字列の末尾を調べるよりString#end_with?を使ったほうが速いというものです。
計測のためのコードを2つに分けました。
理由は match?メソッドです。これはRuby 2.3にはないメソッドだからこのメソッドを含む例と含まない例で分けました。
まずは、match?以外の例の比較。
計測コードは次のとおりです。
# frozen_string_literal: true # rubocop-performance Performance/EndWith require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY REGEX = /bc\Z/ END_STR = 'bc' def bad_sample1 'abc' =~ REGEX end def bad_sample2 'abc'.match(REGEX) end def good_sample 'abc'.end_with?(END_STR) end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ good_sample } end
この結果は次のとおりです。
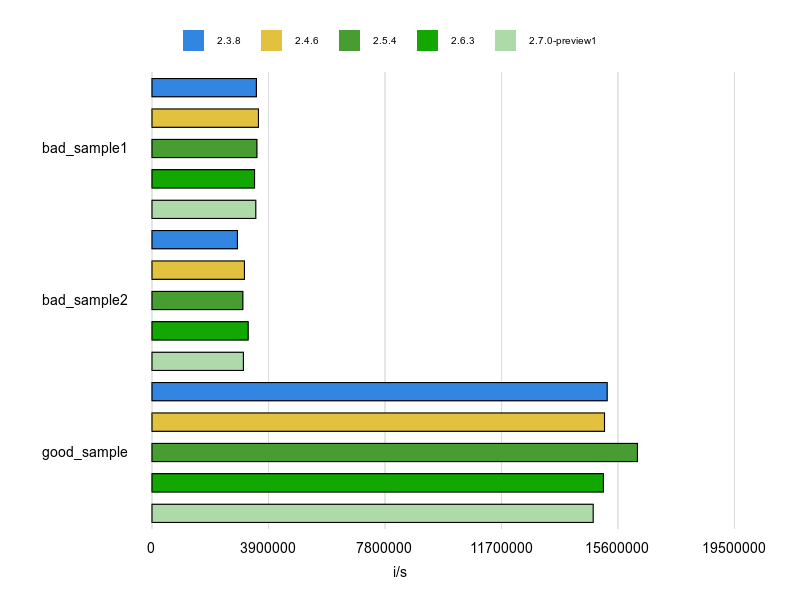
good_sample(String#end_with?)が圧倒的に速いですね。
素直にRubocopに従いましょう。
続いて、match?を含む計測の比較です。
Ruby 2.3以外で比較します。
計測コードは次のとおりです。
# rubocop-performance Performance/EndWith require 'benchmark_driver' output = :gruff versions = ['2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY REGEX = /bc\Z/ END_STR = 'bc' def bad_sample1 'abc'.match?(REGEX) end def bad_sample2 'abc' =~ REGEX end def bad_sample3 'abc'.match(REGEX) end def good_sample 'abc'.end_with?(END_STR) end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ good_sample } end
計測結果は次のとおりです。

bad_sample1(match?)も速いですが、good_sample(end_with?)が更に速いです。
21. Performance/StartWith
最後にString#start_with?です。
match?を含めた比較をします。
なので Ruby 2.3以外での計測です。
計測に使ったコードは次のとおりです。
# rubocop-performance Performance/StartWith require 'benchmark_driver' output = :gruff versions = ['2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY STR = 'abc' RE = /\Aab/ START_STR = 'ab' def bad_sample1 STR.match?(RE) end def bad_sample2 STR =~ RE end def bad_sample3 STR.match(RE) end def good_sample STR.start_with?(START_STR) end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ good_sample } end
計測結果は次のとおりです。
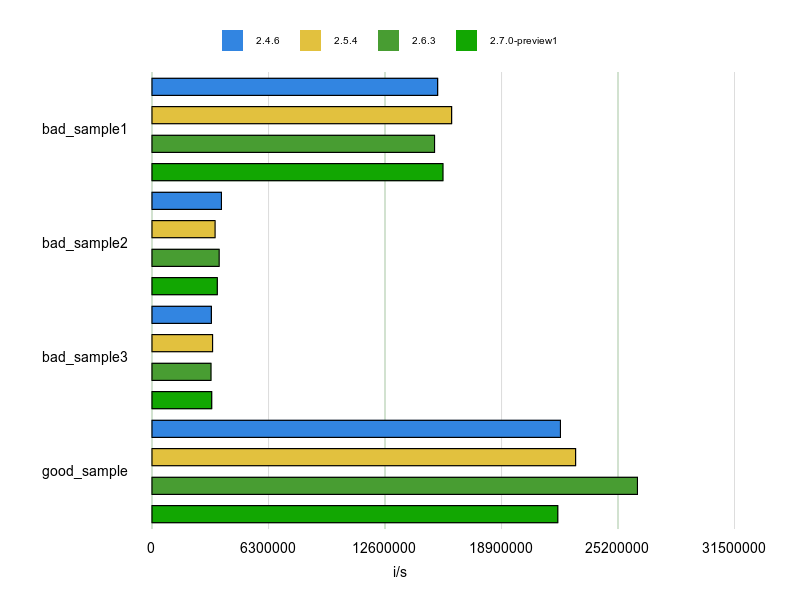
やはりgood_sample(start_with?)は速いですね。
こっちを使っていきましょう。
つづきます
まだまだ Rubocop Perfomanceには Copがありますが、少々長くなってきたので、今回はここまで。
次のエントリに続けます。
最後に
アクトインディではエンジニアを募集しています。 actindi.net