morishitaです。
いこーよでは口コミをもっと投稿しやすく、もっと役立つ情報にしたいと考えています。
口コミを投稿してもらう内容や方法や、それを見てもらう見せ方について議論をしています。
現状の口コミを見つめ直す一環として、機械学習 API を利用して口コミを分析してみました。
目的としては次の 2 点となります。
- 機械学習 API をどの様に利用できるのかを検討するためにまずは使ってみる。
- どの様な口コミが投稿されているのかを機械学習 API を利用して調べてみる。
Cloud Natural Language API とは
Cloud Natural Language APIは Google が提供する機械学習によるテキスト分析サービスです。学習済みのモデルを利用してテキストの分析を行えます。API の形で提供されていて、次の分析の種類があります。
- 構文解析(analyzeSyntax)
- 与えられたテキストを一連の文とトークンに分解します。
- エンティティ分析(analyzeEntities)
- 与えられたテキストに既知のエンティティ(著名人、ランドマークなどの固有名詞、レストラン、競技場などの普通名詞)が含まれているかどうかを調べます。
- 感情分析(analyzeSentiment)
- 与えられたテキストを分析しそれに込められた感情がポジティブか、ネガティブか、ニュートラルかを判断します。
- エンティティ感情分析(analyzeEntitySentiment)
- 与えられたテキスト内の既知のエンティティを抽出してそのテキスト内でのエンティティに込められた感情を判断します。
- コンテンツ分類(classifyText)
- 与えられたテキストを分析して、そのカテゴリを判定します。
今回は感情分析を利用して、いこーよの施設に対して投稿された口コミを分析してみました。
対象となる口コミの抽出条件
分析対象の施設に対する口コミを次の条件で抽出しました。
- 15 文字以上
- 日本語を含んでいる
- リンクを含まない
- test、テスト を含まない
Cloud Natual Language APIで口コミを判定するコード
Ruby のクライアントライブラリが提供されているので、それを利用しました。
CSV で口コミデータを入力し、結果を CSV に出力する次のようなコードで分析しました。
require 'google/cloud/language' require 'csv' class GoogleLang def initialize @language = Google::Cloud::Language.new end def sentiment(text_content) response = @language.analyze_sentiment content: text_content, type: :PLAIN_TEXT sentiment = response.document_sentiment [sentiment.score.round(3), sentiment.magnitude.round(3)] end def analyze_file(file_name) prefix = 'result' output_file = "./results/#{prefix}-#{File.basename(file_name)}" puts output_file write_header = false CSV.open(output_file, 'wb') do |out| CSV.foreach(file_name, headers: true, header_converters: :symbol) do |csv| unless write_header headers = csv.headers out << headers.concat([:score, :magnitude]) write_header = true end text_content = csv[:content] score, magnitude = sentiment text_content csv[:score] = score csv[:magnitude] = magnitude puts "#{csv[:id]}, #{csv[:score]}, #{csv[:magnitude]}" out << csv out.flush sleep 0.2 end end end end if __FILE__ == $0 lang = GoogleLang.new file_name = 'data/experances_of_facility.csv' lang.analyze_file(file_name, verify: false) end
ポイントを説明します。
上記のコードでAPI をコールして結果を得ているのは次のメソッドです。
def sentiment(text_content) response = @language.analyze_sentiment content: text_content, type: :PLAIN_TEXT sentiment = response.document_sentiment [sentiment.score.round(3), sentiment.magnitude.round(3)] end
analyze_sentimentメソッドで API を呼んでいます。
レスポンスには与えたテキスト全体の感情分析結果と、センテンス毎の感情分析も含まれていますが、今回は全体の結果を使っています。
また、感情分析の結果であるscoreとmagnitudeの値も小数点以下の桁数が多い値が帰ってきますが、細かい違いを比較してもしょうがないので丸めています。
また、API の Rate limit はドキュメントによると 100 秒あたり 1000 リクエストとなっていますが、実際には 1 秒あたり 10 リクエストで考えたほうが良いようです。なので少し余裕を持って 200msec のスリープをはさみながらループを回しています。
結果
感情分析の結果は与えたテキスト全体とセンテンス毎の判定結果の2種類が返ってきます。今回はテキスト全体の結果を利用しています。 その結果はscoreとmagnitudeの 2 つの値によって示されます1。
scoreは感情の振れ幅を表します。-1.0〜1.0 の値をとり、大きいほどポジティブで有ることを示します。テキストにポジティブな表現とネガティブな表現が混在する場合には相殺した値がテキスト全体の score となります。また、正の値だからといってポジティブ、負の値だからネガティブと考えるべきではなく、0付近の値はニュートラルと見るべき値のようです。今回はscoreの値の範囲をざっくり三等分して次の様に考えることにしました2。
- -1.0 〜-0.3:ネガティブ
- -0.3 〜 0.3:ニュートラル
- 0.3 〜 1.0:ポジティブ
magnitudeは感情の度合いを表します。正の数で示され、大きいほどその感情が強いことを表します。テキスト内で感情が表現されるごとに加算されるとのことなので、テキストが長いと値が多くなる傾向があります。
実際、今回対象とした口コミの文字数とmagnitudeの関係は次の様になり、ドキュメントの記述通りの傾向があります。
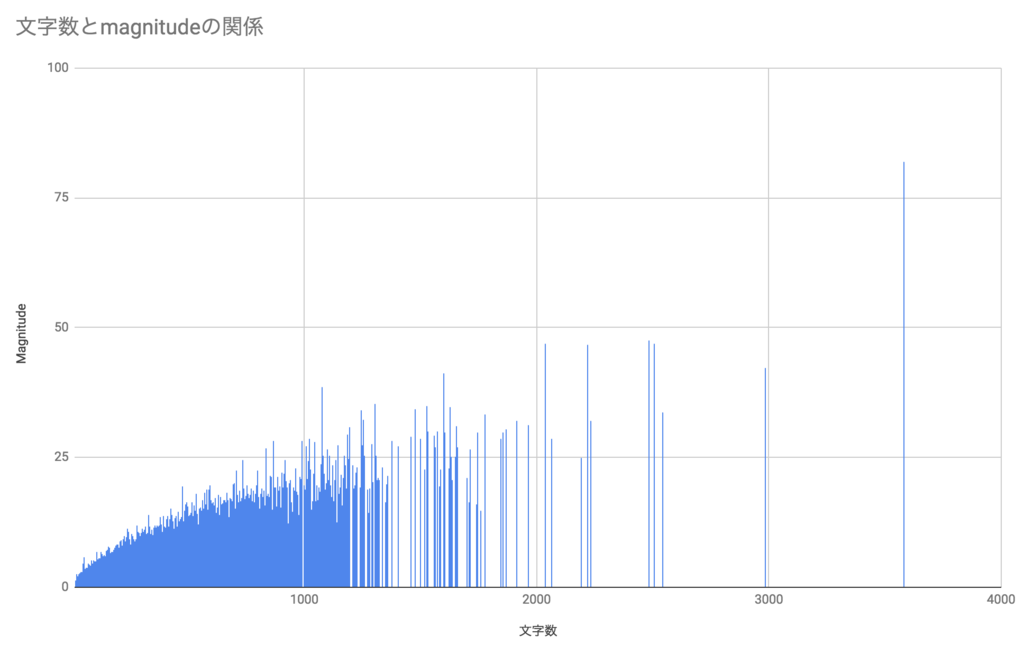
ちなみに、文字数毎の口コミの分布は次のようになります。 ほとんどの口コミは300文字以下のようです。

ネガポジの分布
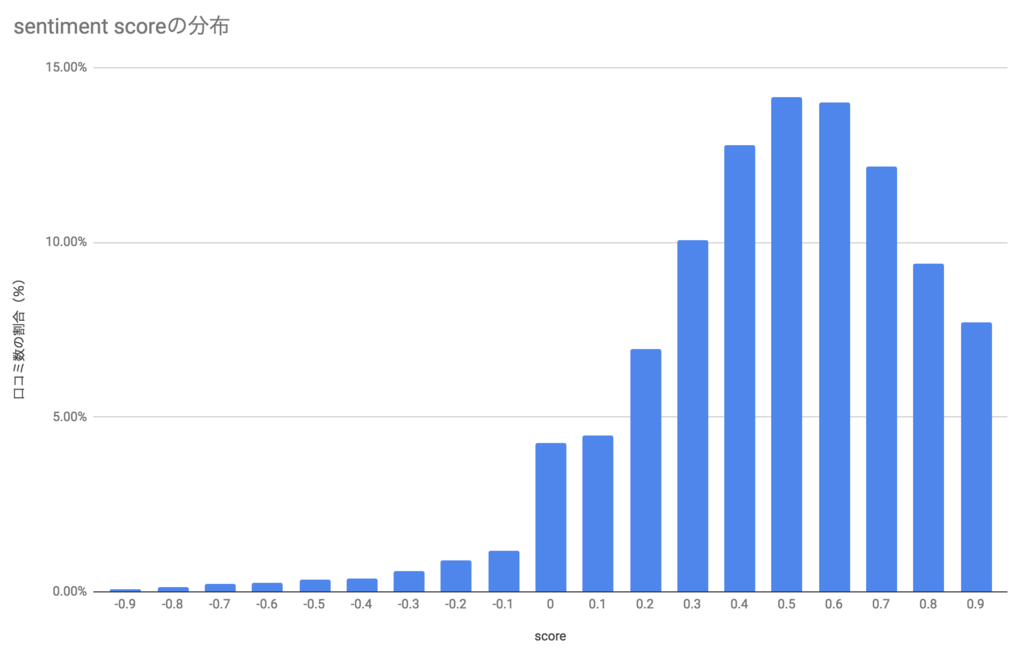
さて、Cloud Natual Language API で判定した結果を見ていきましょう。 感情の振れ幅であるscoreの分布は次の様になりました。
いこーよでは、口コミを見たユーザがハッピーな気持ちになり「行ってみたい」「体験してみたい」と思ってもらいたいと考えています。 Cloud Natual Language APIの判定結果によると、現状ではその様な口コミサービスを運営できているようです。
scoreと文字数の関係
続いて、文字数とscoreの関係を見てみました。
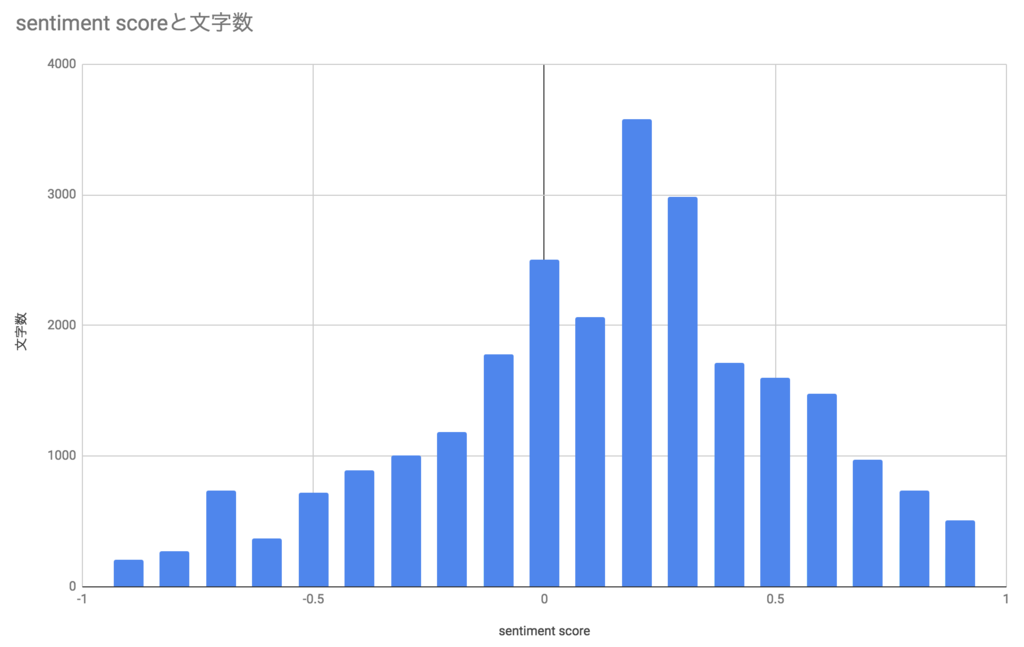
文字数が多少と感情の振れ幅にはあまり相関はなさそうです。
score と magnitude の関係
最後はscoreとmagnitudeの関係です。
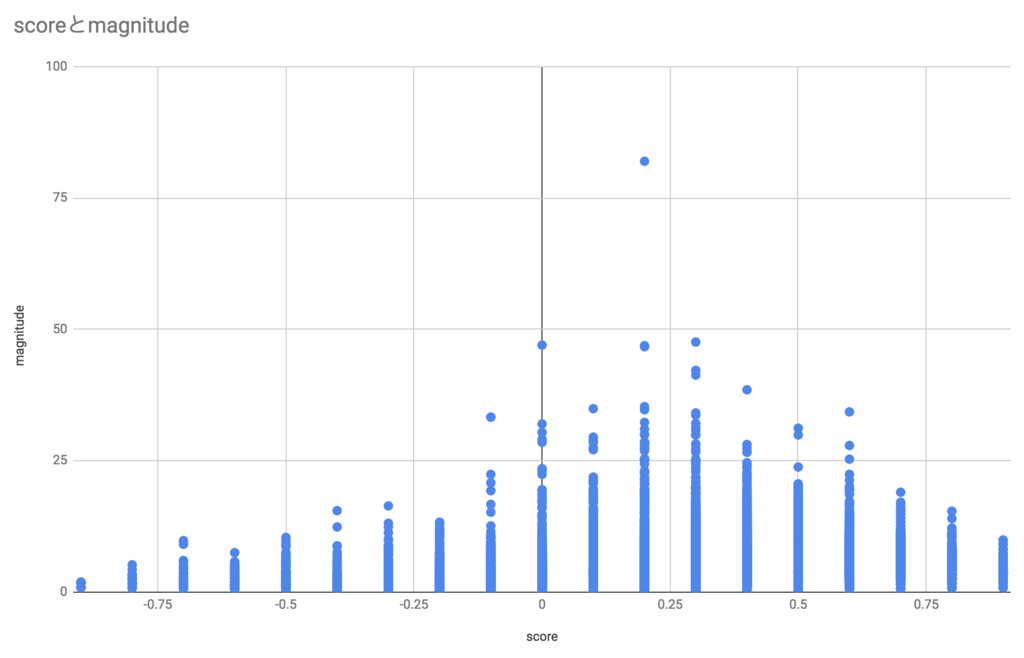
特にscoreの絶対値が大きいものがmagnitudeも大きいというわけでもなさそうです。 magnitudeが大きいものは文字数も大きい傾向があるので、長い口コミではネガティブなこともポジティブなことも含んでおり全体としてはニュートラルに寄っていくのかもしれません。
まとめ
今回はとりあえずやってみたというところです。 実サービスに組み込むとするとどの様に利用できるかは今後の検討となります。
すぐに思いつくものとしては次の用途が考えられます。
- 定期的にscoreの分布を見て、サービス運営者として期待通り運営できているかをチェックする
- Cloud Natual Language APIによる一次チェックで極端にネガティブなものはユーザ評価とは言えず誹謗中傷になっている可能性があるとして確認してから掲載するようにする
- Cloud Natual Language APIによる一次チェックで極端にポジティブなものはスパムでないかチェック対象にする。
もっとも、実サービスで利用する前にはCloud Natual Language APIの個々の口コミに対する判定結果を見て、その確からしさを評価し、ネガ/ポジのしきい値を決定する必要があるでしょう。
最後に
アクトインディでは一緒に口コミをより良くしていくエンジニアを募集しています。
-
https://cloud.google.com/natural-language/docs/basics#sentiment-analysis-values↩
-
きちんと運用するならば、実際の判定結果をみてネガ/ポジのしきい値を調整すべきだと思います。今回は試してみたというレベルなのでざっくりです。↩