morishitaです。
前々回、前回から続くrubocop-performanceの指摘事項について盲従せずに確認してみるシリーズの最終回です。
前編、中編はこちらです。
計測について
計測には BenchmarkDriver を利用しました。
Rubocopのドキュメントに bad と good の例が掲載されていますが、基本的にはそれをBenchmarkDriverで計測してみて比較しました。
例をなるべく変更せずに計測する方針で行いましたが、文字列、配列、ハッシュなどは定数にして使い回すようにしています。
各 Cop が論点にしているポイントだけをなるべく計測するため、これらの生成コストを計測に含めないようにするためです。
計測に利用したコードはこのエントリにも掲載しますが、次のリポジトリにも置いておきます。
rubocop-performance-measurements
単に bad と good を計測するだけでなく複数のRubyのバージョンで計測しています。
一応、Rubocopはまだ、Ruby 2.3 をサポートしているようなので、
それ以降のバージョンということで次のRubyバージョンで計測しました。
- 2.3.8
- 2.4.6
- 2.5.4
- 2.6.3
- 2.7.0-preview1
一部、Ruby 2.3.8 では実装されていないメソッドに関する Cop では 2.3.8 を除外して計測しました。
結果は秒あたりの実行回数 ips (Iteration per second = i/s)で示します。
各結果ともbenchmark_driver-output-gruffによるグラフで示しますが、グラフが長いほうが高速ということです。
また、結果の値自体は計測環境の性能により変わります。
なので、サンプル間の差に着目してください。
では順に見ていきます。
18. Performance/RegexpMatch
Ruby 2.4 で追加された String#match?、Regexp#match?、Symbol#match? は matchより速いので使いましょうという Cop ですね。
戻り値であるMatchDataを使わず正規表現にマッチしているかどうかだけ見るなら、match?を使った方がいいよってことですね。
次のコードで計測しました。
# rubocop-performance Performance/RegexpMatch require 'benchmark_driver' output = :gruff versions = ['2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def do_something(arg = nil) 1 + 1 end X = 'regex-match' RE = /re/ def bad_sample1 if X =~ RE do_something end end def bad_sample2 if X !~ RE do_something end end def bad_sample3 if X.match(RE) do_something end end def bad_sample4 if RE === X do_something end end def good_sample1 if X.match?(RE) do_something end end def good_sample2 if !X.match?(RE) do_something end end def good_sample3 if X =~ RE do_something(Regexp.last_match) end end def good_sample4 if X.match(RE) do_something($~) end end def good_sample5 if RE === X do_something($~) end end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ bad_sample4 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } x.report %{ good_sample4 } x.report %{ good_sample5 } end
計測結果は次のとおりです。
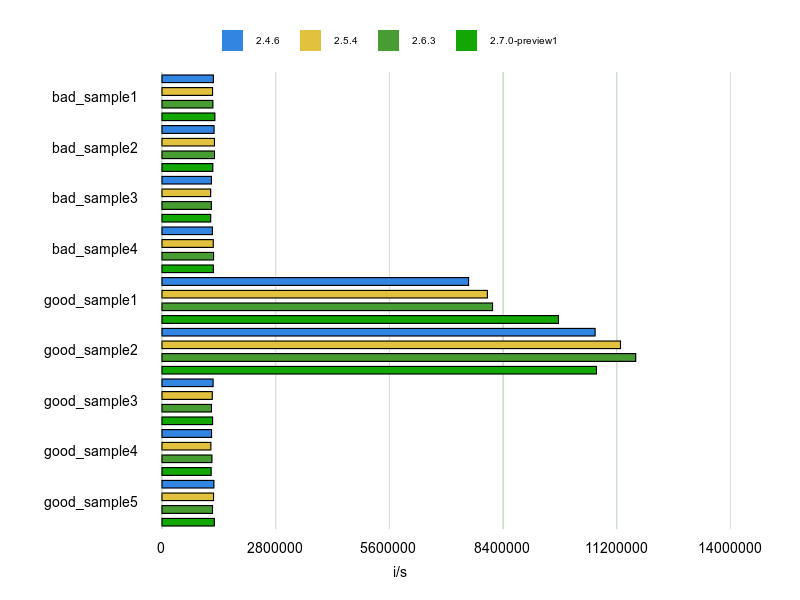
match?を使うgood_sample1、good_sample2の結果が突出しています。
good_sample1 より good_sample2 が速いのは、if文の中が実行されていないためです。
good_sample3、good_sample4、good_sample5は match? を使ってなくて速くないですが、正規表現のマッチ結果を後の処理で使っているならOKですよっていう例ですね。
19. Performance/ReverseEach
reverse.each の代わりに reverse_each を使いましょうという Cop です。
次のコードで計測しました。
# rubocop-performance Performance/ReverseEach require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY ARRAY = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] def bad_sample ARRAY.reverse.each end def good_sample ARRAY.reverse_each end RUBY x.report %{ bad_sample } x.report %{ good_sample } end
計測結果は次のとおりです。
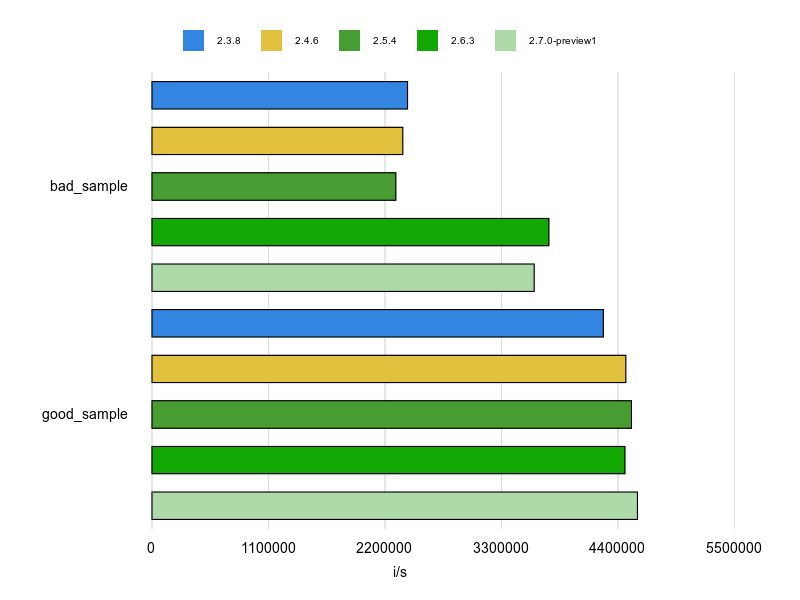
なるほど。reverse_eachを使ったほうがパフォーマンスがいいですね。
reverse_each、使っていきましょう。
20. Performance/Size
Array や Hash の大きさを求める場合、count より size を使いましょうという Cop です。size は length のエイリアスなので、どちらを使っても同じです1。
計測に利用したコードは次のとおりです。
# rubocop-performance Performance/Size require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY ARRAY = [1, 2, 3] HASH = {a: 1, b: 2, c: 3} def bad_sample1 ARRAY.count end def bad_sample2 HASH.count end def good_sample1 ARRAY.size end def good_sample2 HASH.size end def good_sample3 ARRAY.count { |e| e > 2 } end def good_sample4 HASH.count { |k, v| v > 2 } end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } x.report %{ good_sample4 } end
計測結果は次のとおりです。
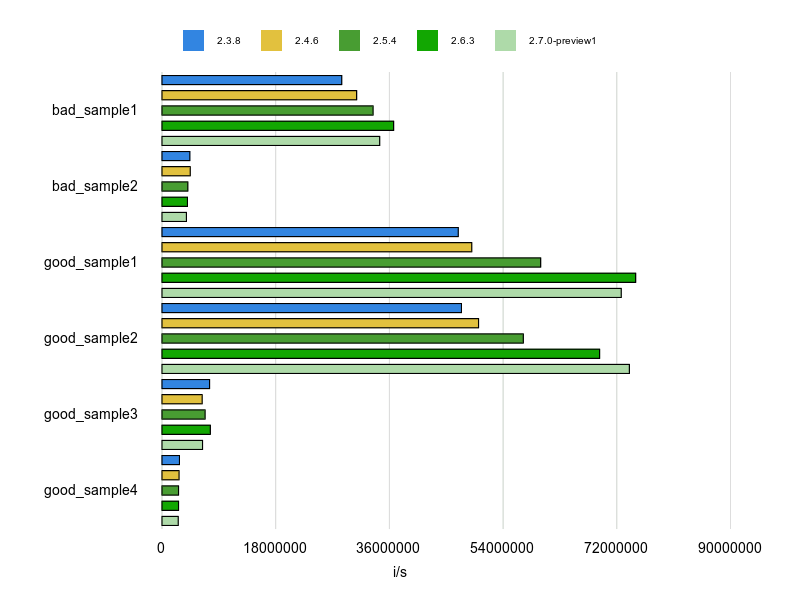
good_sample1(Array#size) と good_sample2(Hash#size) を見ると効果は大きいですね。
特にbad_sample2(Hash#count) と good_sample2(Hash#size) を比べると、Hash#count は使っちゃダメだろうって思いますね。
ただし、countには使いみちがあります。配列やハッシュの要素から条件を満たす要素を選択的に数えたい場合です。その例が good_sample3 と good_sample4 です。
前編の Performance/Count で見ましたが、Array#select{}.size よりも Array#count{} の方がパフォーマンスが良いので、この場合には count を使うほうがいいでしょう。
この条件を満たすものだけ数える機能のため、countでは要素をループで数えるので遅いのですね。
22. Performance/StringReplacement
文字列の中の1文字を他の文字で置き換えるなら、gsub ではなく tr や delete を使おうという Cop です。
次のコードで計測しました。
# rubocop-performance Performance/StringReplacement require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY STR = 'abc' STR_WS = 'a b c' def bad_sample1 STR.gsub('b', 'd') end def bad_sample2 STR.gsub('a', '') end def bad_sample3 STR.gsub(/a/, 'd') end def bad_sample4 'abc'.gsub!('a', 'd') end def good_sample1 STR.gsub(/.*/, 'a') end def good_sample2 STR.gsub(/a+/, 'd') end def good_sample3 STR.tr('b', 'd') end def good_sample4 STR_WS.delete(' ') end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ bad_sample4 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } x.report %{ good_sample4 } end
計測結果は次のとおりです。
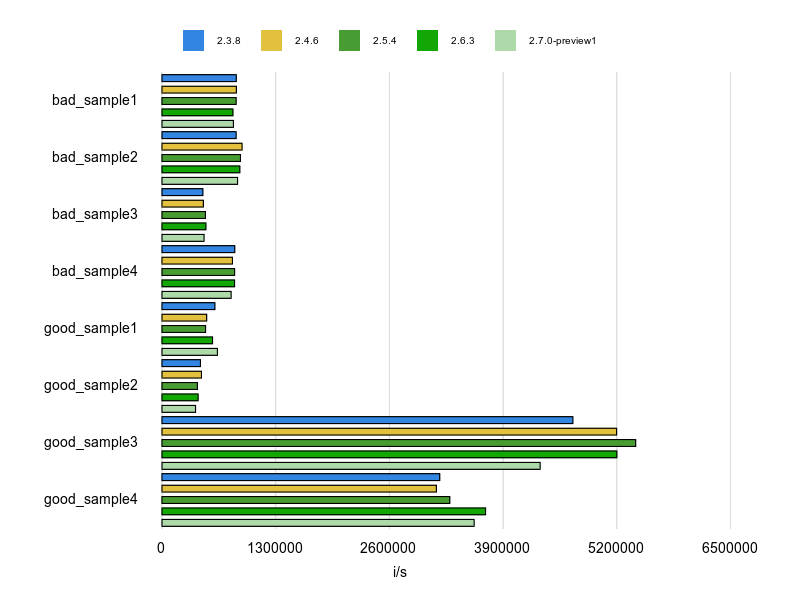
good_sample3、good_sample4 の結果を見るとString#tr と String#delete の効果は大きいですね。
スペースの除去に String#gsub(' ', '') を使ってしまっていたこともある気がするので今後は String#delete(' ')を使うようにしたいと思います。
String#trの使いみちがいまいちわかりにくいかのですが、このメソッドは単に1文字を置換するものではありません。
'あかさたな'.tr("あ-ん", "ア-ン") => 'アカサタナ' の様なことができる使いようによっては便利なメソッドです2。
good_sample1 と good_sample2 は gsub を使うべきケースです。単なる文字置換でなく正規表現にマッチした文字を置換しています。
23. Performance/TimesMap
決まった回数を繰り返して配列を作る時に、.times.map を使うより、繰り返し数の大きさのArrayインスタンスを作ったほうがいいよという Cop です。
文字で説明してもわかりにくいので計測に使った次のコードを見てください。
# rubocop-performance Performance/TimesMap require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def bad_sample 9.times.map do |i| i.to_s end end def good_sample Array.new(9) do |i| i.to_s end end RUBY x.report %{ bad_sample } x.report %{ good_sample } end
計測結果は次のとおりです。
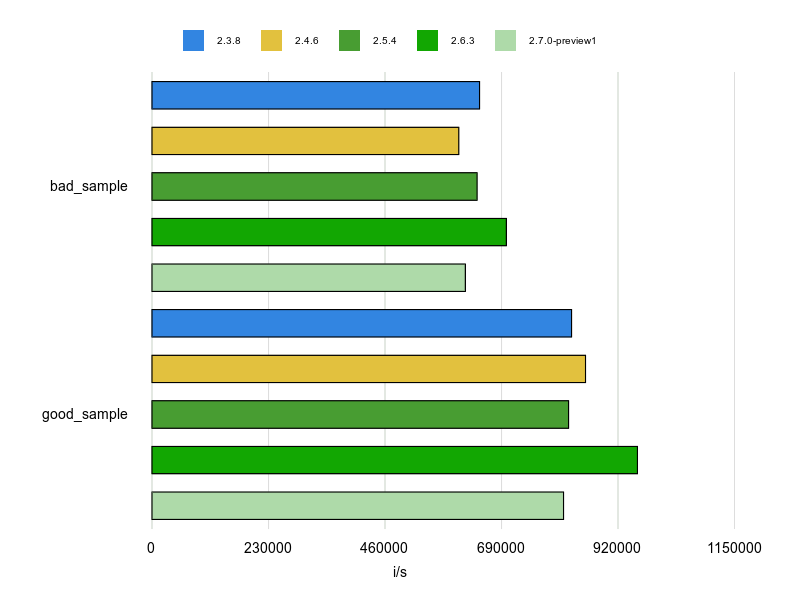
good_sample(Array.new) の方が確かにパフォーマンスがいいですね。
24. Performance/UnfreezeString
フリーズされた文字列をアンフリーズするためにString#dup や String.new を使うよりも単項の +演算子を使うほうが速いですよという Cop です。
計測コードは次のとおりです。
# rubocop-performance Performance/UnfreezeString require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def bad_sample1 ''.dup end def bad_sample2 'something'.dup end def bad_sample3 String.new end def bad_sample4 String.new('') end def bad_sample5 String.new('something') end def good_sample1 +'something' end def good_sample2 +'' end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ bad_sample4 } x.report %{ bad_sample5 } x.report %{ good_sample1 } x.report %{ good_sample2 } end
計測結果は次のとおりです。
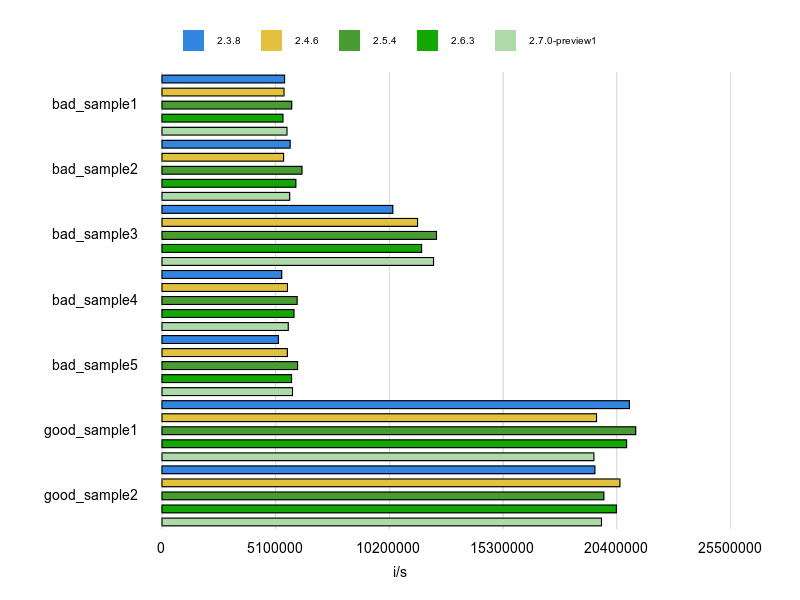
確かに、good_sample1、good_sample2 のパフォーマンスはいいです。
ただ、フリーズされた文字列をアンフリーズするケースがあんまり思い当たりません。
将来的に文字列はデフォルトでフリーズされるという話もありますが、そうなれば便利なのでしょうか。
25. Performance/UriDefaultParser
最後は URI::Parser.new より URI::DEFAULT_PARSER を使おうという Cop です。
URLをパースして解析したい場合に使うのだと思います。
ただ、これらより URI.parse を使うことが多いではないでしょうか。なので、URI.parse も加えて計測してみました。そのコードを次に示します。
Rubocopのドキュメントでは単に、パーサーを取得するだけですが、実際にURLをパースしてみるコードで比較しました。
# rubocop-performance Performance/UriDefaultParser require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output, runner: :time) do |x| x.rbenv *versions x.prelude <<~RUBY URL_STR = 'https://www.sample.com' def bad_sample URI::Parser.new.parse(URL_STR) end def good_sample URI::DEFAULT_PARSER.parse(URL_STR) end def exstra_sample URI.parse(URL_STR) end RUBY x.report %{ bad_sample } x.report %{ good_sample } x.report %{ exstra_sample } end
計測結果は次のとおりです。
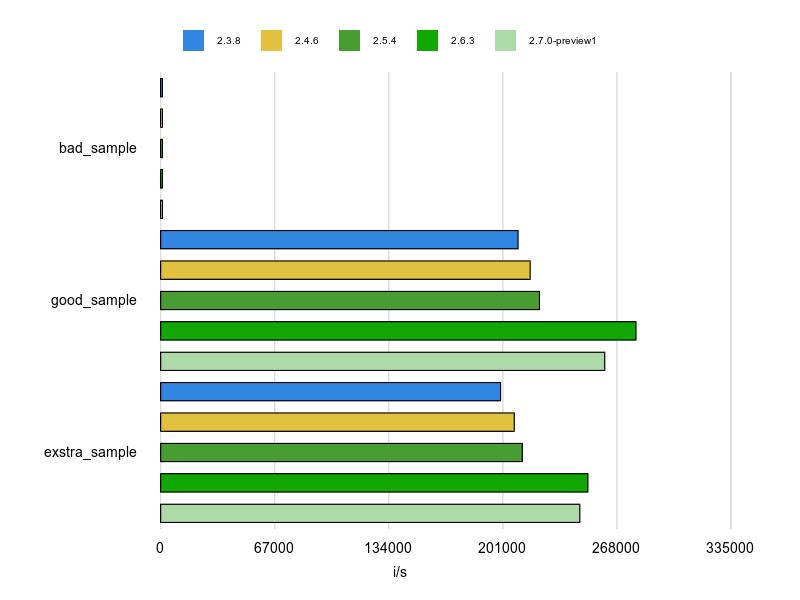
サンプルのコードはいずれもURLのパースの結果として URI::HTTPS のインスタンスを生成します。
bad_sample(URI::Parser.new)は話にならないですね。
私がよく使う exstra_sample(URI.parse)もまあ、速いのですが、good_sample(URI::DEFAULT_PARSER)は更に速いですね。
一通り見てみて
さて、これで一通り Rubocop Performance を実際に計測して、その結果を見てみました。
概ね指摘されたら従ったほうが良さそうだとわかりました。
弊社でRubyというともっぱらRailsのアプリケーション開発ですが、あるメソッド内の1行であってもそれが、別のメソッドのループ内で使われることもありますし、アクセス数がとても多いページの処理で使われていたりします。1回ごとのコストは微々たるものでも減らす努力をするとサーバの負荷軽減、ひいては快適なユーザ体験につながるのでパフォーマンスにも気を使ったコードを書くようにしたいと思います。
パフォーマンス改善に優位性がないどころか、かえって遅くなったものについては今後、各プロダクトでRubocopルールに反映するかを考えたいと思います。
Rails内での利用を想定して計測方法や操作対象の配列やハッシュなどの大きさを見直して検証し直す必要があるかもしれません。
Rubocopは開発を効率的にするためにつかうもので、便利でとても有用なツールです。
ただ、プロダクトの性質やチームの方針により何を「効率的」とするのかは開発速度だったり、読みやすくメンテしやすいことだったり様々だと思いますし、プロダクトやチームの成長段階とともに変わることもあると思います。
うまく活用して開発していきたいと思います。
おまけ
もう一つ、計測してみて思ったことがあります。
それはリテラルで文字列、配列、ハッシュを生成するのは結構なコストなのだなということです。
最初は計測コード中の配列やハッシュを各メソッド内で生成していました。でも、bad と good の結果にほとんど差が出ない Cop があり、試しに定数に変えてみると差が際立ちました。これらの生成コストが支配的であったということですね。それで今回の計測に使ったコードでは極力リテラルでオブジェクトの生成をしないように変更しました。
加えてRubyバージョンが上がるに連れリテラルの生成が高速化されているということを感じました。
で、実際に次のコードで文字列、配列、ハッシュの生成を計測してみました。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY URL_STR = 'https://www.sample.com' def string_literal 'string literal' end def array_literal [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] end def hash_literal { a: 1, b: 2, c: 3, d: 4, e: 5, f: 6, g: 7, h: 8, i: 9, j: 0 } end RUBY x.report %{ string_literal } x.report %{ array_literal } x.report %{ hash_literal } end
この計測結果は次のとおりです。
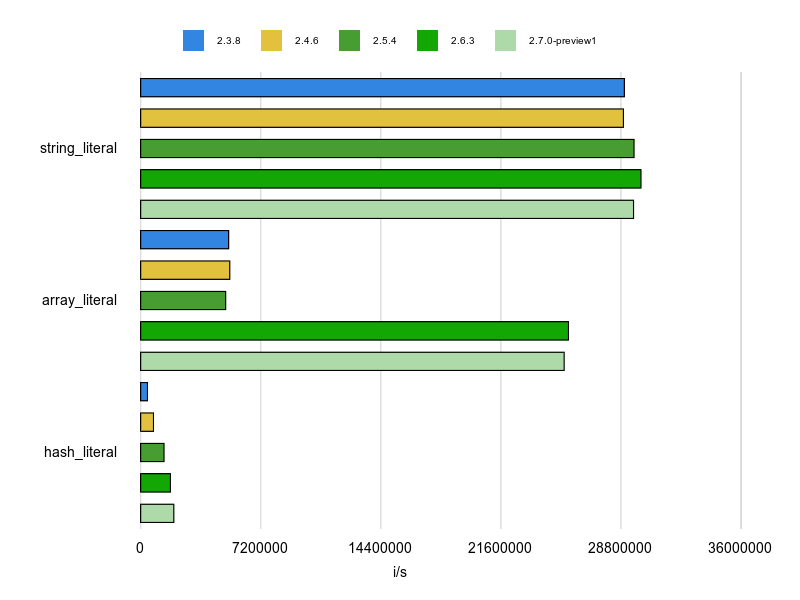
Stringは Ruby 2.5 以降、若干ですが改善しています。
Arrayは Ruby 2.6 で大幅な改善がなされています。
Hashはバージョンを経るごとにだんだん改善されています。
Rubyのバージョンは新しいものほど着実にパフォーマンスアップされていますね。
最後に
アクトインディではエンジニアを募集しています。 actindi.net