morishitaです。
前回のエントリーの続き、rubocop-performanceの指摘事項について盲従せずに確認してみるシリーズの2回目です。
前編はこちら。
計測について
計測には BenchmarkDriver を利用しました。
Rubocopのドキュメントに bad と good の例が掲載されていますが、基本的にはそれをBenchmarkDriverで計測してみて比較しました。
例をなるべく変更せずに計測する方針で行いましたが、文字列、配列、ハッシュなどは定数にして使い回すようにしています。
各 Cop が論点にしているポイントだけをなるべく計測するため、これらの生成コストを計測に含めないようにするためです。
計測に利用したコードはこのエントリにも掲載しますが、次のリポジトリにも置いておきます。
rubocop-performance-measurements
単に bad と good を計測するだけでなく複数のRubyのバージョンで計測しています。
一応、Rubocopはまだ、Ruby 2.3 をサポートしているようなので、
それ以降のバージョンということで次のRubyバージョンで計測しました。
- 2.3.8
- 2.4.6
- 2.5.4
- 2.6.3
- 2.7.0-preview1
一部、Ruby 2.3.8 では実装されていないメソッドに関する Cop では 2.3.8 を除外して計測しました。
結果は秒あたりの実行回数 ips (Iteration per second = i/s)で示します。
各結果ともbenchmark_driver-output-gruffによるグラフで示しますが、グラフが長いほうが高速ということです。
また、結果の値自体は計測環境の性能により変わります。
なので、サンプル間の差に着目してください。
では順に見ていきます。
10. Performance/FixedSize
最初からなんなんですが、固定の値を求めるのはやめようってことで当たり前なので計測は割愛します。
ドキュメントの悪い例を見ると、文字列や配列、ハッシュのリテラルに対してsizeメソッドやcountメソッドを使っていますが、それはやめましょう。コードを書いた時点でわかっている値です。
一方、変数に入った文字列や配列、ハッシュ、あるいは一部の値が splat展開される配列やハッシュでsizeメソッドやcountメソッドを使うのは良い例となっています。変数の中身は実行時に変わるので、OKということですね。
11. Performance/FlatMap
flatten(引数あり)よりもflat_mapやflatten(引数なし)を使いましょうという Cop です。
次のコードで計測しました。
# rubocop-performance Performance/FlatMap require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY ARRAY = [1, 2, 3, 4] def bad_sample1 ARRAY.map { |e| [e, e] }.flatten(1) end def bad_sample2 ARRAY.collect { |e| [e, e] }.flatten(1) end def good_sample1 ARRAY.flat_map { |e| [e, e] } end def good_sample2 ARRAY.map { |e| [e, e] }.flatten end def good_sample3 ARRAY.collect { |e| [e, e] }.flatten end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } end
計測結果は次のとおり。
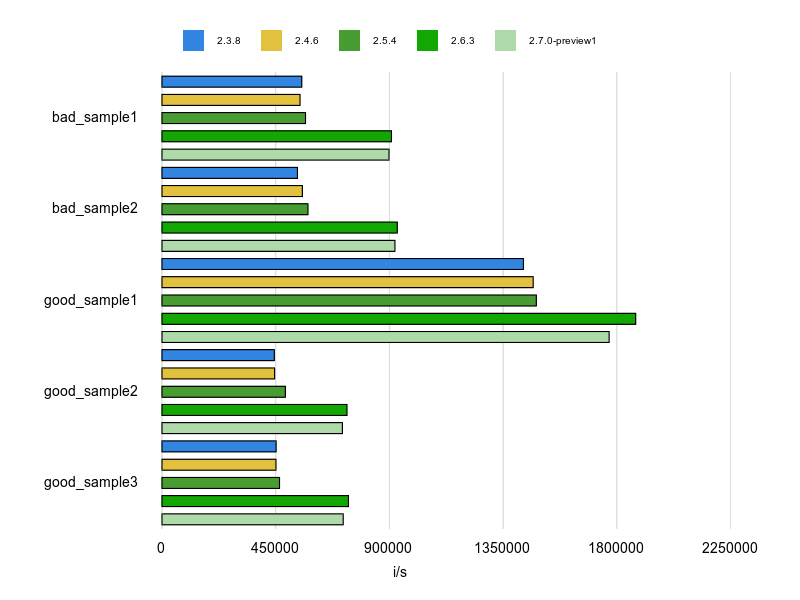
うーん、good_sample1(flat_map)は効果ありと思うのですが、flattenは逆に遅くなってますね。
flat_mapを使っていきましょう。
12. Performance/InefficientHashSearch
ハッシュがあるキーや値を持つかどうかを調べるにはHash#keys.include? や Hash#values.include?よりも Hash#key? や Hash#value? を使いましょうという Cop です。
ちょっと例が多いので、キーと値で計測を分けました。
Hash#key?、Hash#has_key?
まずはキーの計測コードから。
# rubocop-performance Performance/InefficientHashSearch require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY HASH = { a: 1, b: 2 } def bad_sample_key1 HASH.keys.include?(:a) end def bad_sample_key2 HASH.keys.include?(:z) end def bad_sample_key3 h = { a: 1, b: 2 }; h.keys.include?(100) end def good_sample_key1 HASH.key?(:a) end def good_sample_key2 HASH.has_key?(:z) end def good_sample_key3 h = { a: 1, b: 2 }; h.key?(100) end RUBY x.report %{ bad_sample_key1 } x.report %{ bad_sample_key2 } x.report %{ bad_sample_key3 } x.report %{ good_sample_key1 } x.report %{ good_sample_key2 } x.report %{ good_sample_key3 } end
この計測結果は次のとおりです。
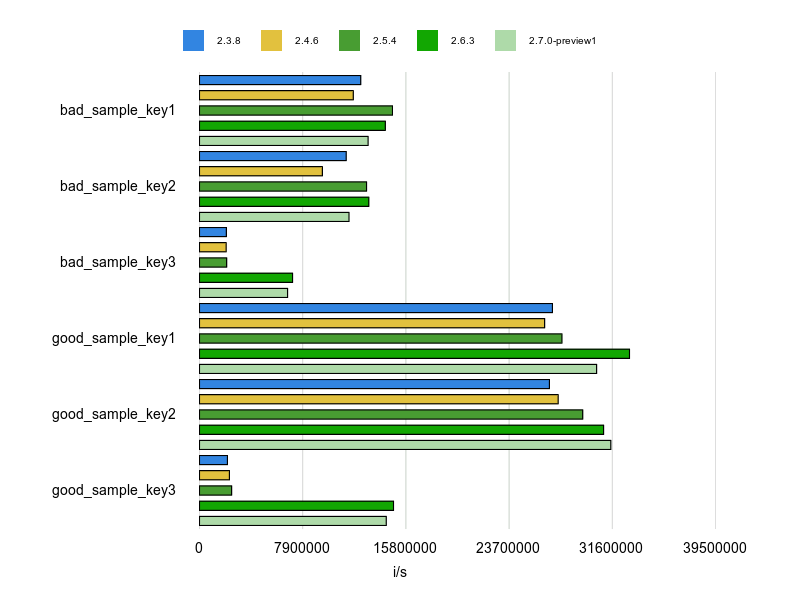
good_sample_key1(Hash#key?)とgood_sample_key2(Hash#has_key?)のパフォーマンスの良さが際立ちますね。素直にRubocopの指摘に従ったほうがいいでしょう。
bad_sample_key3とgood_sample_key3の遅さが目立ちますがこれはメソッド内でハッシュを生成してしまっているからだと思います。ドキュメントにあったので入れましたが、他の例と比べて必要性が薄いので外しても良かったかもしれません。
Hash#value?、Hash#has_value?
そして値についての計測コードは次のとおりです。
# rubocop-performance Performance/InefficientHashSearch require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY HASH = { a: 1, b: 2 } def bad_sample_value1 HASH.values.include?(2) end def bad_sample_value2 HASH.values.include?('garbage') end def bad_sample_value3 h = { a: 1, b: 2 }; h.values.include?(nil) end def good_sample_value1 HASH.value?(2) end def good_sample_value2 HASH.has_value?('garbage') end def good_sample_value3 h = { a: 1, b: 2 }; h.value?(nil) end RUBY x.report %{ bad_sample_value1 } x.report %{ bad_sample_value2 } x.report %{ bad_sample_value3 } x.report %{ good_sample_value1 } x.report %{ good_sample_value2 } x.report %{ good_sample_value3 } end
計測結果は次のとおりです。
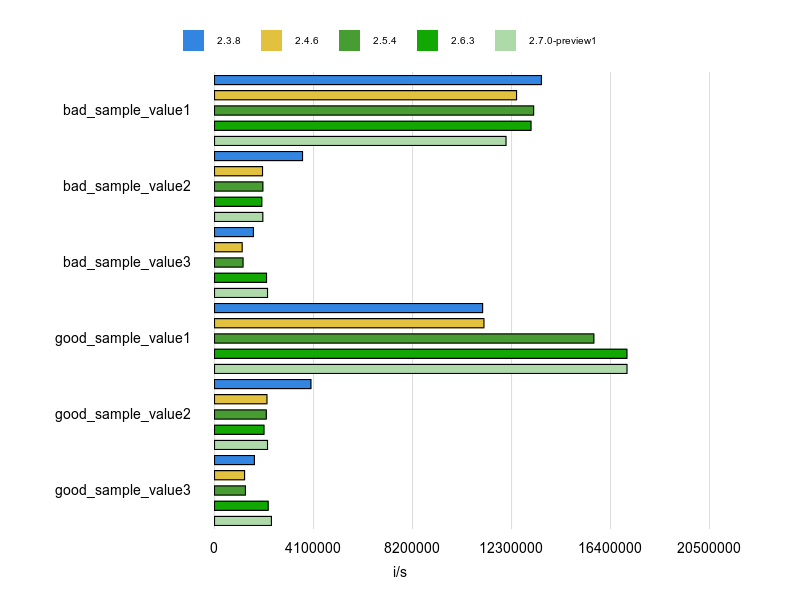
bad_sample_value1に比べてgood_sample_value1(Hash#value?)のパフォーマンスはいいです。
一方、bad_sample_value2に対して good_sample_value2(has_value?)はあんまり効果が見られません。
使うならば、Hash#value?を使うのがいいでしょう。
そのHash#value?にしてもRuby 2.3, 2.4では逆に遅くなっています。Rubyのアップデートについていくのも大事ですね。
13. Performance/OpenStruct
OpenStructは要素を動的に追加・削除できる手軽な構造体を提供するクラスです。
このOpenStructを使うのやめましょうという Cop です。
計測用のコードは次のとおりです。
# rubocop-performance Performance/OpenStruct require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY require 'ostruct' class BadClass def my_method OpenStruct.new(my_key1: 'my_value1', my_key2: 'my_value2') end end class GoodClass MyStruct = Struct.new(:my_key1, :my_key2) def my_method MyStruct.new('my_value1', 'my_value2') end end def bad_sample BadClass.new.my_method end def good_sample GoodClass.new.my_method end RUBY x.report %{ bad_sample } x.report %{ good_sample } end
計測結果は次の様になります。
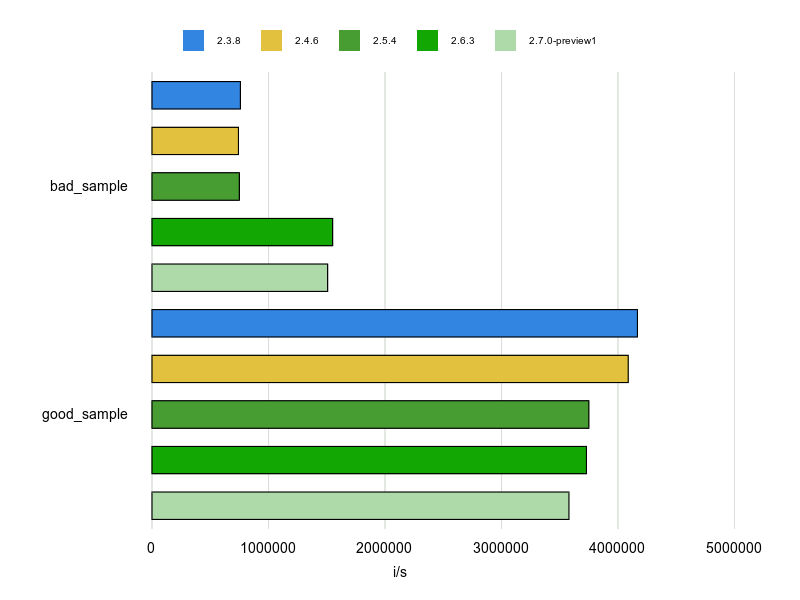
結果は一目瞭然ですね。
OpenStructは便利ですが、パフォーマンスにシビアなコードでは使わないほうが良さそうです。
14. Performance/RangeInclude
Range#include? の代わりにRange#cover?を使いましょうという Cop です。
Range#include?は Range 内の値を1つづつ===でチェックしますが、Range#cover?は始点と終点を<=>で比較するだけです。ほとんどの場合はRange#cover?で十分でしょうというのがこの Cop の説明です。
ただし、処理の内容が異なる以上、結果が異なるケースがあるので注意が必要です。 例えば次の結果は異なるので注意が必要です。
('a'..'z').include?('yellow') # => false ('a'..'z').cover?('yellow') # => true
一括置換するのは危険ですよってことですね。
計測に使ったコードは次のとおりです。
# rubocop-performance Performance/RangeInclude require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY RANGE = ('a'..'z') def bad_sample RANGE.include?('b') end def good_sample RANGE.cover?('b') end RUBY x.report %{ bad_sample } x.report %{ good_sample } end
この計測結果は次のとおりです。
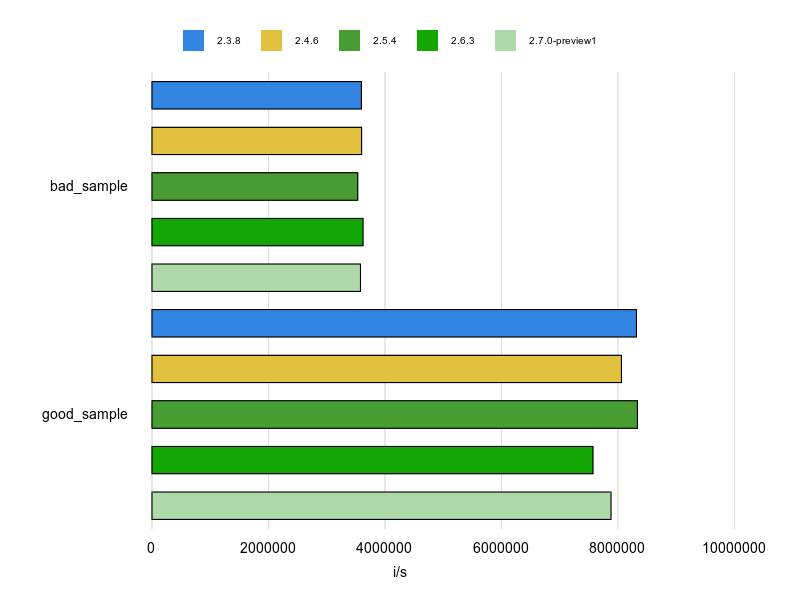
注意は必要ですが、使える場合には Range#cover? を積極的に使っていったほうが良さそうですね。
15. Performance/RedundantBlockCall
メソッドでブロックを受け取る場合、ブロック引数&blockを取って block.call を呼ぶよりもyeildがパフォーマンス的に有利ですよっていう Cop です。
計測コードは次のとおりです。
# rubocop-performance Performance/RedundantBlockCall require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def bad_method(&block) block.call end def bad_another(&func) func.call 1, 2, 3 end def good_method yield end def good_another yield 1, 2, 3 end def bad_sample1 bad_method { 1 + 2 } end def bad_sample2 bad_another { |a, b, c | a + b + c } end def good_sample1 good_method { 1 + 2 } end def good_sample2 good_another { |a, b, c | a + b + c } end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ good_sample1 } x.report %{ good_sample2 } end
計測結果は次のとおりです。
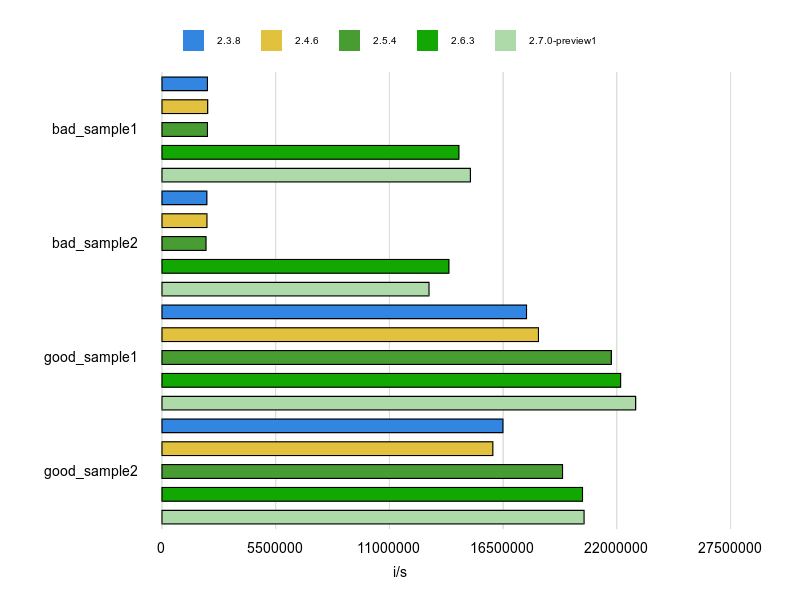
Ruby 2.6 以降では &block引数 + block.call もパフォーマンス改善されていますが、yeild には及びません。
ただ、yeildだと、メソッドシグネチャ見ただけでブロックを取れることがわかりにくいので、行数が多い大きなメソッドで使うと見通しが悪くなるかもなと思います。
まあ、それ以前にRubocopの Metrics系の Cop にメソッドが大きすぎると指摘されるでしょうけど。
16. Performance/RedundantMatch
Regexp#matchより=~の方が高性能だよっていう Cop です。が、Regexp#match を =~ で置き換えられる場面というのは match? で事足りる場合がほとんどでなのではないでしょうか1。割愛します。
17. Performance/RedundantMerge
Hash#merge! よりも Hash#[]= の方が高性能なので使いましょうねという Cop です。
次のコードで計測しました。
# rubocop-performance Performance/RedundantMerge require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def bad_sample1 { x: 10, y: 20, z: 30 }.merge!(a: 1) end def bad_sample2 { x: 10, y: 20, z: 30 }.merge!({'key' => 'value'}) end def bad_sample3 { x: 10, y: 20, z: 30 }.merge!(a: 1, b: 2) end def good_sample1 hash = { x: 10, y: 20, z: 30 } hash[:a] = 1 end def good_sample2 hash = { x: 10, y: 20, z: 30 } hash['key'] = 'value' end def good_sample3 hash = { x: 10, y: 20, z: 30 } hash[:a] = 1 hash[:b] = 2 end RUBY x.report %{ bad_sample1 } x.report %{ bad_sample2 } x.report %{ bad_sample3 } x.report %{ good_sample1 } x.report %{ good_sample2 } x.report %{ good_sample3 } end
計測結果は次の通りです。
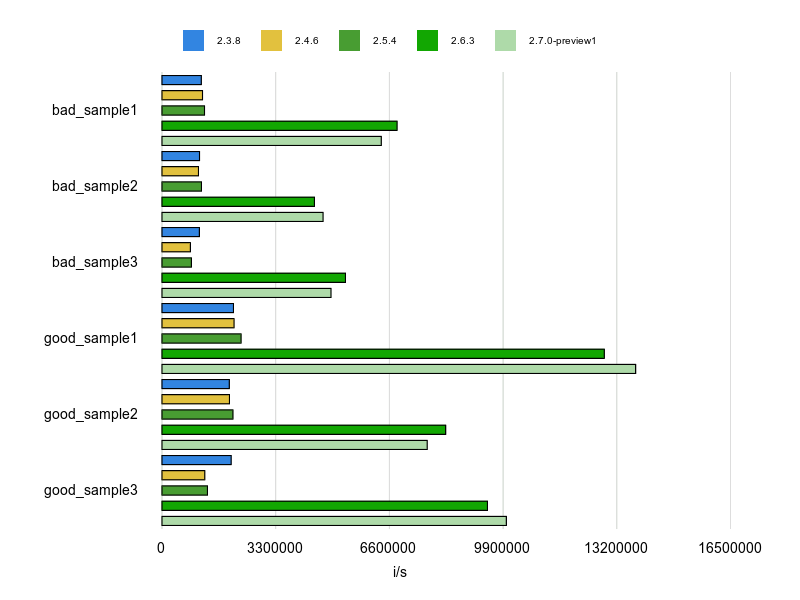
結果はHash#[]= の方が速いですが、マージするハッシュが大きいとコードが見にくくなります。
Rubocopのデフォルト設定ではキーの数が2つ以下だと指摘するようになっています。
キーが多いハッシュはHash#merge!を使ってコードをすっきりさせようってことですかね。
Ruby 2.6、2.7でグラフが伸びているのはハッシュリテラル生成の性能が上がっているからですかね。
まだ続きます。
さて、Rubocop Perfomanceにはもう少し Cop が残っていますが、本エントリではここまで。次回に続けます。
最後に
アクトインディではエンジニアを募集しています。 actindi.net
-
match?に関するCop は Performance/RegexpMatch があります。次回、後編で紹介します。↩