morishitaです。
この記事はactindi Advent Calendar 2018 - Adventarの3日目の記事です。
2018年12月1日、「いこーよ」は10周年を迎えました。
すでに終了したものも含めて10周年企画として次を実施しています。
お出かけスポット無料チケット配布以外のキャンペーンはまだまだ募集中なので奮ってご応募ください!プレゼントも用意しています!
さて、上記のうち、2つの企画でGASアプリケーションを活用しました。
このエントリではそれらについて紹介します。
tl;dr
- 社内で使う管理ツールをGASで作りました
- その中でS3へのファイルアップロードやVue.jsの利用を行いました
- ちょっとした管理アプリケーションを実装するプラットフォームとしてGASの便利さを実感しました。
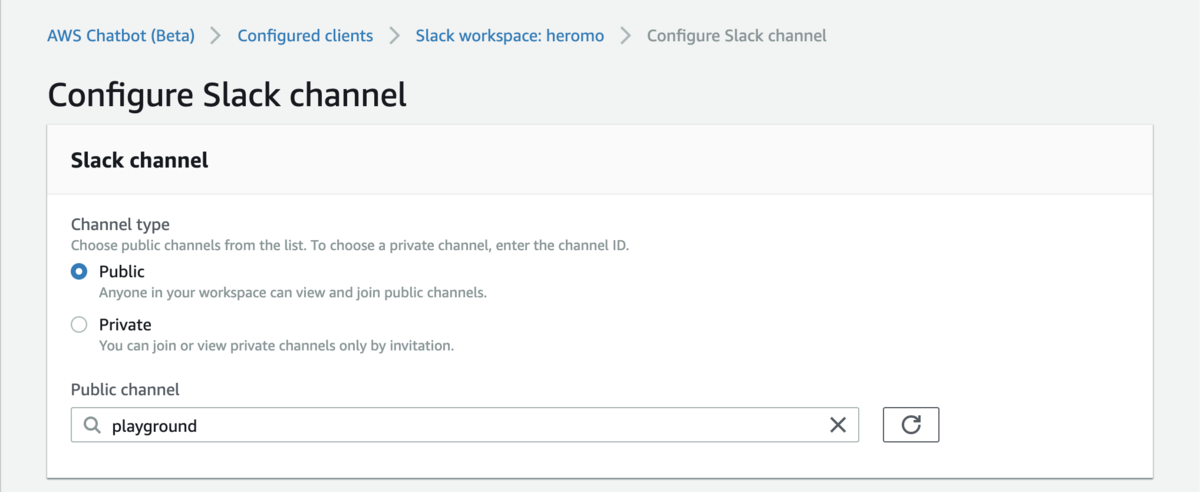
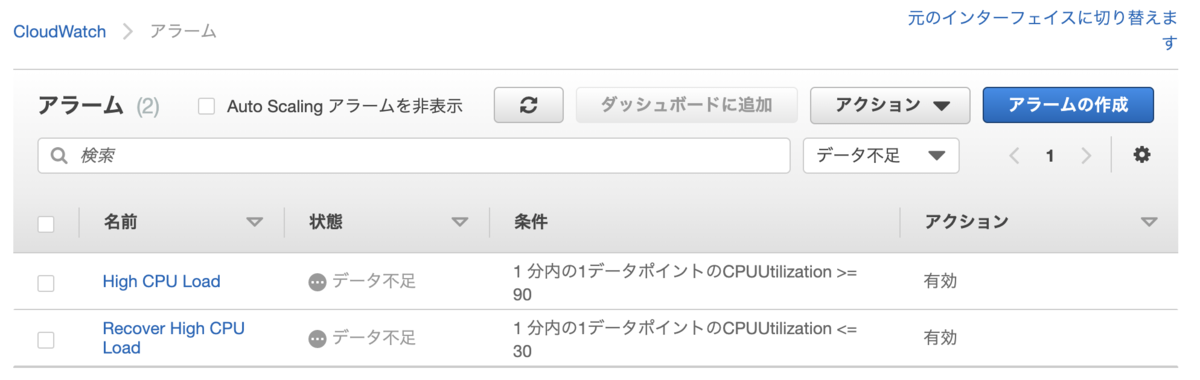
お出かけスポット無料チケット配布の管理画面
すでに企画自体は終了してしまっているのですが、
「お出かけスポット無料チケット配布」は全国135の施設様にご協力いただき入場料などの無料チケットを配布するというものでした。
ユーザの皆様に見ていただくWebサイトはNuxtで実装したSPAでした。
それについては次のエントリでで紹介しました。
tech.actindi.net
そこに掲載する施設様の情報を管理するための仕組みが必要だったのですが、それをGASで実装しました。
管理アプリケーションの要件は次の通り。
- 無料チケットを提供してくださる施設様の約150件の情報を管理できること
- 施設様の追加、情報の更新は任意のタイミングで可能なこと
- 12月1日は施設様からの連絡があればすぐに配布を終了できること
管理すべき情報の総数が大きくないのと、できるだけ運用を手軽にするために社内で普段から活用しており、運用担当者も使い慣れているGoogle シートで管理できるようにしました。
その情報をJSONとしてS3にアップロードしてユーザのみなさんがアクセスするNuxtのSPAで参照するという仕組みにしました。
図で表すと次の様な感じです。

特徴的な技術要素としては次の2つを含んでいます1。
- AWS S3へのファイルアップロード
- カスタムメニュー
AWS S3へのファイルアップロード
GoogleシートにはAPIもあるので直接SPAから参照することも出来はします。
しかし、それほどレスポンスが速くないのと、APIの呼び出し回数の制限2に引っかかりそうだったのでJSONに変換したものをS3にアップロードしそれを参照させることにしました。
GASからS3にファイルアップロードする方法ですが、次のライブラリを使えば簡単です。
github.com
開発者の方のブログはこちら。
Amazon S3 API Binding for Google Apps Script | Engineering | Etc
この使い方を説明します。
まずはライブラリの追加します。
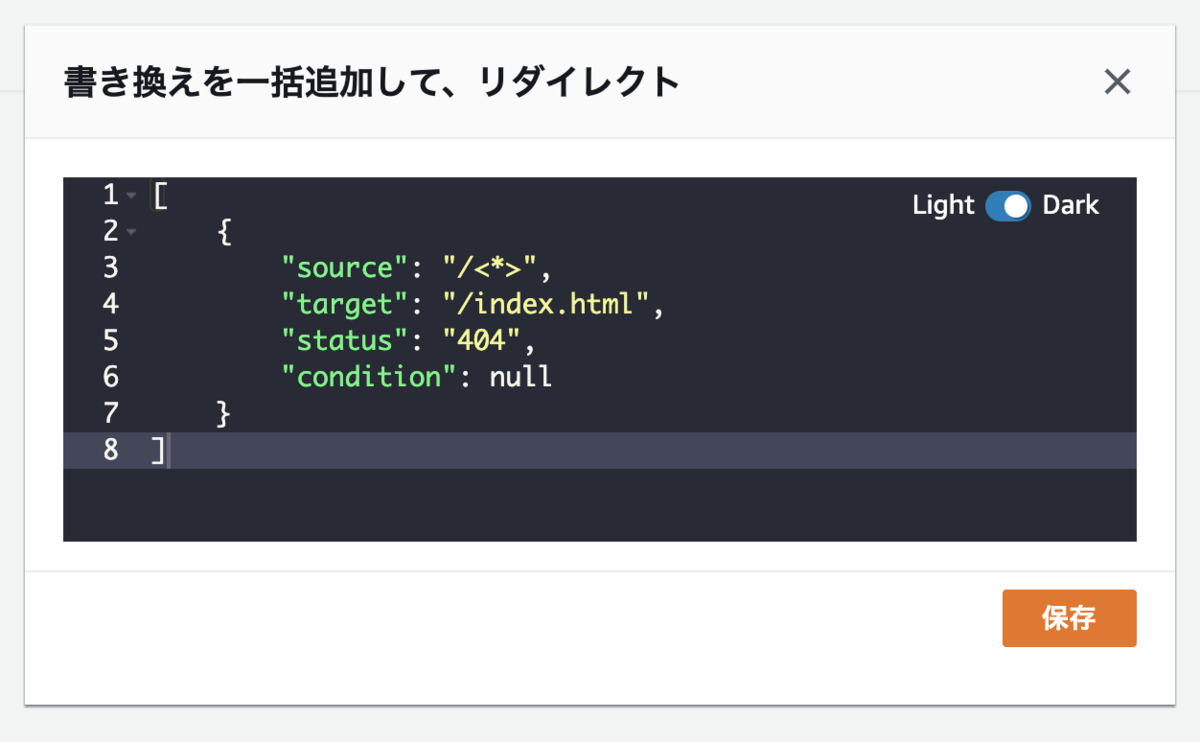
GASのスクリプトエディタの[リソース]-[ライブラリ]を選択すると次のダイアログが開きます。

そのダイアログの「ライブラリを追加」に MB4837UymyETXyn8cv3fNXZc9ncYTrHL9 と入力して、ライブラリを追加します。
これだけです。
claspを使っている場合には application.json に次を追加してもいいかと思います。
{
"timeZone": "Asia/Tokyo",
"dependencies": {
"libraries": [{
"userSymbol": "S3",
"libraryId": "1Qx-smYQLJ2B6ae7Pncbf_8QdFaNm0f-br4pbDg0DXsJ9mZJPdFcIEkw_",
"version": "4"
}]
},
"exceptionLogging": "STACKDRIVER"
}
後は次のようなコードでファイルをアップロードできます。
この例ではGASの実行環境の時刻serverTimeを記載したJSONファイルを指定バケットのdata/time.jsonに書き込む例です。
try {
const s3 = S3.getInstance(AWS_ACCESS_KEY, AWS_SECRET_ACCESS_KEY);
const uploadData = { serverTime: Utilities.formatDate(new Date(), 'GMT', "yyyy-MM-dd'T'HH:mm:ss'Z'") }
s3.putObject(S3_BUCKET_NAME, 'data/time.json', uploadData);
} catch (error) {
console.error('ファイルの更新に失敗しました');
}
アップロードされたファイルの中身はこんな感じです。
{"serverTime":"2018-12-02T23:00:33Z"}
簡単ですね。
簡単なのですが、MB4837UymyETXyn8cv3fNXZc9ncYTrHL9 というIDで参照できるものとGithubに上がっているコード同じものか?ということを確認するすべはおそらくありません。
(2019/08/11追記)私の無知でした。GASのスクリプトをライブラリとして一般公開するためにはそのGASプロジェクトの共有設定で公開する必要があります。Webエディタのライブラリ設定ダイアログを開くとライブラリ名がリンクになっています。そのリンクを開くとライブラリのバージョン一覧みたいなページが開きます。そのURLにGASプロジェクトのIDが含まれています。それさえわかればWebエディタが開けるのでライブラリとして公開されているソースも見ることができます。このS3ライブラリの場合、S3がソースとなります。(2019/08/11追記ここまで)
今回はS3バケット内はすべてパブリック公開しており、そのバケットへの操作だけを許可されたIAMアカウントを使っているので、仮に悪意あるライブラリがホストされており、アップロードするデータやIAMのキーが盗まれたとしても被害がその範囲に限定されているためそのまま利用しています。しかしセンシティブなデータを扱うケースでは自前でライブラリをホストし直して利用するほうがいいかもしれません。ご利用は自己責任でお願いします。
今回の「お出かけスポット無料チケット配布」では管理シート全体をJSONに変換してS3にアップロードしました。
それをNuxtのSPAから取得してコンテンツとして表示しています。
カスタムメニュー
さて、スプレッドシートの編集は任意のタイミングで行いますが、入力のたびにJSONファイルに反映しては編集途中の情報がユーザに見えてしまいます。編集後、アップロードのタイミングは運用担当者が決めたいということで、アップロードをトリガーする方法が必要となりました。
運用担当者は非エンジニアなので、「スクリプトエディタで関数を実行してください」というのは避けたいところです。
そこで選択するだけサクッとアップロード処理を実行できるように次のようなカスタムメニューを作りました。

次のコードで上記のメニューを作成できます。
function addMenu(): void {
const ss = SpreadsheetApp.getActiveSpreadsheet();
ss.addMenu('アップロードメニュー', [
{name: 'アップロード', functionName: 'uploadToS3'},
{name: '最終更新時刻を確認する', functionName: 'showLastUploadTime'},
{name: '設定を開く', functionName: 'openSettingDialog'},
]);
}
「アップロード」というメニューを選択するとuploadToS3という関数が実行されます。uploadToS3はスプレッドシートをJSONに変換してS3にアップロードする関数です。
ただ、addMenuという関数を作っただけではメニューは表示されません。
GASのスクリプトエディタの[編集]-[現在のプロジェクトのトリガー]を選択して、新規トリガーとして次の様なトリガーを追加します3。

これで、スプレッドシートを開くたびにaddMenu関数が実行されメニューが表示されるようになります。
笑顔写真の管理画面
もう1つ、笑顔写真大募集でもGASを活用した管理アプリケーションを作成しました。
笑顔写真はいこーよのスマホアプリからお子様の笑顔の写真を投稿してもらうという企画です。投稿された写真はいこーよ内の特設ページで公開されています。
管理アプリケーションの要件は次のとおりでした。
- 投稿された写真を掲載前に確認し、掲載可否を判断できること
- 掲載OKの写真はいこーよ内に掲載することができること
- 一度掲載した写真も後から取り下げることができること
無邪気な子供の笑顔写真投稿に掲載可否判定の審査なんているの? と思われるかもしれませんが、投稿された写真におち○ちんがモロに写っている場合などを考慮しこの様な運用をしています4。先日のTumblrのようになっても困るので。
上記の要件を満たすように作った仕組みは次のとおりです。

スマホアプリから投稿された写真は、Firebaseのストレージに格納され、URLなどの情報がGoogleシートに書き込まれます。
今回作成したGASアプリケーションで掲載可否を判断し、
掲載OKとなった写真は、GASアプリ上の操作からいこーよの写真登録APIをコールします。その結果、前述の特設ページに掲載されます。
却下した写真は、それを記録します。
掲載後、やっぱり取り下げたい場合には掲載日や投稿時のメールアドレスなどから検索して取り下げることができます。
GASのWEBアプリケーションとして実装しそのUIは次の様になっています。

このGASアプリケーションの特徴はVue.jsを利用していることです。
最初は仕組みを複雑にしたくなかったので、UI上のJSはバニラで実装して、辛いところだけちょこっとJQueryを使おうかなと思っていました。
しかし、いざやり始めると使い勝手よくするために思ったよりJSの量が増えてしまいました。また、普段Vueを使うことが多く、すっかりJQueryを体が受け付けなくなっていたのもありVueをGASを上で使ってみることにしました。
GAS上でのVue.js
いろいろ設定とか大変かなと思いましたが、トランスパイル不要な範囲だとGAS上でVue.jsを使うのはそれほど難しくはありません。
次の様にCDNから配信されているVueのライブラリをGASのHTMLテンプレートに追加してやるだけで使えるようになります。
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.17/dist/vue.js"></script>
ライブラリが読み込めれば、後は通常のVueアプリを作る要領で実装できます。
<div id="app">
// アプリのUI
/* 〜略〜 */
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.17/dist/vue.js"></script>
<script type="text/javascript">
var app = new Vue({
el: '#app',
components: {
'smile-photo': SmilePhoto,
'photo-modal': PhotoModal,
},
data: {
photos: JSON.parse("<?=uncheckedPhotos?>"),
},
computed: {
photo_count() {
return this.photos.length;
}
},
methods: {
}
});
</script>
上記はGASのHtmlService.createTemplateFromFileに読み込ませるHTMLテンプレートの抜粋ですが、それを読み込むコードは次のとおりです。
function doGet(e: any): GoogleAppsScript.HTML.HtmlOutput {
const template = HtmlService.createTemplateFromFile('index') as IExtendedTemplate;
template.data = JSON.stringify(readSpreadsheet());
const htmlOutput = template.evaluate();
return htmlOutput;
}
この中で readSpreadsheetというスプレッドシートを読み出す関数をJSON文字列化してtemplate.uncheckedPhotosに代入しています。これはHTMLテンプレート内の次のコードで参照され、HTMLの一部5として展開されます。
data: {
photos: JSON.parse("<?=data?>"),
},
こうしてスプレッドシートの内容をVueアプリケーションが保持するデータとして渡すことができます。
単一ファイルコンポーネントっぽいものの実装
さて、これでインタラクティブなUIが作りやすくなりましたが、実装量が増えてくると分割したくなります。
Vueではコンポーネントに分割していきますが、GAS上でもそれは変わりません。
VueではUIとロジックを1ファイルに書ける単一ファイルコンポーネントが便利ですが、今回はトランスパイル等しないので使えません。
でも、単一ファイルコンポーネントもどきなら実装できます。
笑顔写真を表示する次の部分をコンポーネントとして切り出しました。

そのコードが次のとおりです6。
<script type="text/template" id="smile-photo-tmplate">
<div class="card" style="width: 245px;">
<div class="card-image">
<img :src="photo.photo_url" class="img-responsive img-fit-cover" :title="photo.uuid" :class="{done: isAccepted||isRejected}" @click="$emit('show-modal', photo)">
</div>
<div class="card-header">
<div class="card-title">
<span class="label label-success" v-if="photo.status === 'accepted'">掲載中</span>
<span class="label label-error" v-else-if="photo.status === 'rejected'">掲載却下</span>
<span class="label label-warning" v-else-if="photo.status === 'canceled'">掲載取下</span>
<span class="label" v-else>未判断</span>
</div>
<div class="card-subtitle text-gray">
<span v-if="photo.status === 'accepted'">掲載日:{{photo.published_at}}</span>
<span v-else-if="photo.status === 'rejected'">却下日:{{photo.updated_at}}</span>
<span v-else-if="photo.status === 'canceled'">取下日:{{photo.updated_at}}</span>
</div>
</div>
<div class="card-body">
<div class="container">
<div class="columns">
<div class="column col-6">
<button class="btn btn-primary" @click="accept" :class="[{loading: isProcessing}, {'btn-success': isAccepted}]" :disabled="isProcessing||isAccepted">掲載する</button>
</div>
<div class="column col-6">
<button class="btn" @click="reject" :class="[{loading: isProcessing}, {'btn-error': isRejected}]" :disabled="isProcessing||isRejected">掲載しない</button>
</div>
</div>
</div>
</div>
</div>
</script>
<script type="text/javascript">
var STATUS = {
ACCEPTED: 'accepted',
REJECTED: 'rejected',
CANCELED: 'canceled',
}
var SmilePhoto = {
template: '#smile-photo-tmplate',
props: ['photo'],
data: function() {
return {
isProcessing: false,
modal: false
}
},
computed: {
isAccepted() {
return this.photo.status === STATUS.ACCEPTED;
},
isRejected() {
return this.photo.status === STATUS.REJECTED || this.photo.status === STATUS.CANCELED;
}
},
methods: {
accept(){
this.isProcessing = true;
google.script.run
.withSuccessHandler(this._onSuccess.bind(this))
.withFailureHandler(this._onFailure.bind(this))
.accept(this.photo.uuid)
},
reject(){
this.isProcessing = true;
google.script.run
.withSuccessHandler(this._onSuccess.bind(this))
.withFailureHandler(this._onFailure.bind(this))
.reject(this.photo.uuid)
},
_onSuccess(updatedPhoto) {
Object.assign(this.photo, updatedPhoto);
this.isProcessing = false;
console.log({accept: 'success',uuid: this.photo.uuid, iko_yo_id: this.photo.iko_yo_id})
},
_onFailure() {
this.isProcessing = false;
console.log({accept: 'failure',uuid: this.photo.uuid})
}
}
};
</script>
UIテンプレートは <script type="text/template">の中に書き込み、Vueコンポーネントから参照しています。
これを components/smile-photo.html というファイルに保存して、使いたいGASのHTMLテンプレート内で次の様に読み込みます。
<?!= HtmlService.createHtmlOutputFromFile('components/smile-photo').getContent(); ?>
HtmlService.createHtmlOutputFromFileはGASのユーティリティー関数で指定したファイルを読み込んでHTMLとして挿入してくれます。
後は、コンポーネントとしてVueアプリにSmilePhotoを登録すれば使えます。
まとめ
キャンペーンなど一時的な機能の追加が必要で、しかもそのためのデータの登録、更新が必要であれば、何らかの管理機能が必要になります。
でも、どうせ使い捨て機能だしプロダクト本体に実装するのは避けたい。
という場合の1つのソリューションとして、GoogleシートとGASを組み合わせて実現した実例をご紹介しました。
エンドユーザからのアクセスがあるような箇所で適用するにはデータをS3等にアップロードし、それをアプリケーションから利用することで速度やAPIの制限を超えることができました。
大量のデータを扱う必要のあるケースでは処理が遅くて無理かもしれません。
しかし、今回の笑顔写真大募集の場合であれば、約3000枚の写真を表示し処理してみましたが、問題なく使えました。
管理画面の実装だと操作できるユーザの認証も必要となりますが、Googleアカウントで共有する形なので、自前で実装する必要がありません。
そしてサーバレスで運用できます。
とても便利です。
最後に
アクトインディでは、長くメンテナンスするプロダクトでは運用性やメンテナンス性を検討しながら開発を進めます。が、今回のような使い捨てな場合にはこれまでのやり方にとらわれず場合、場合に最適なやり方で開発を進めます。
そんな環境で一緒に開発したいエンジニアを募集しています。
actindi.net