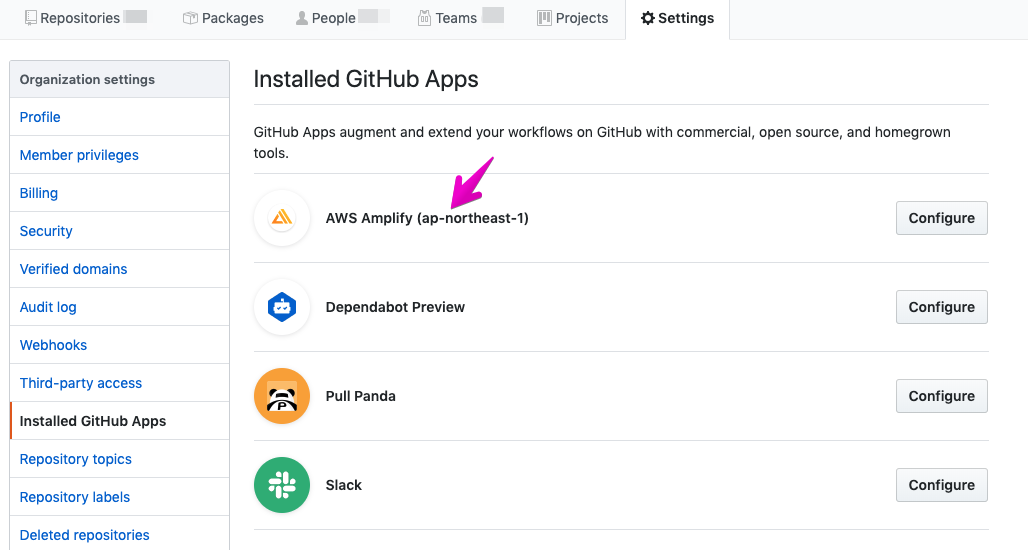
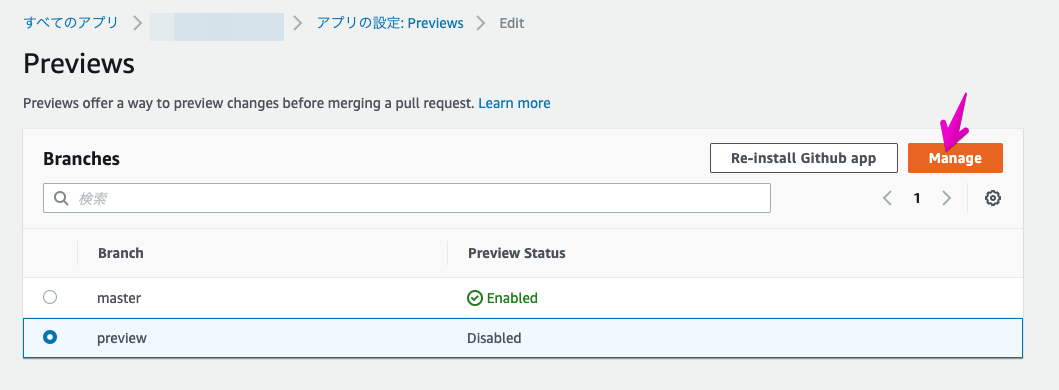
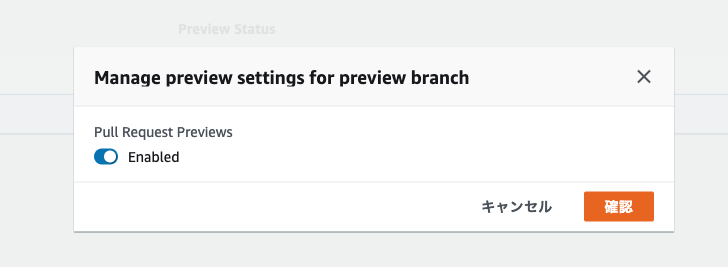
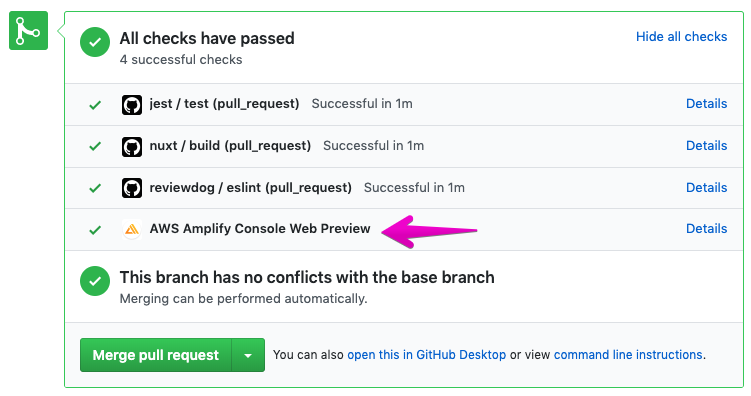
morishitaです。
yamamotoが次のエントリで紹介しましたが、いこーよを Kubernetes 上で運用し始めて3ヶ月になろうとしています。
まあトラブルもありますし、やってみてEC2で運用していたのとは勝手が違うところに苦労しつつですが、移行してよかったと思っています。
移行前の状況
いこーよは弊社のメインサービスであり、最も長くメンテナンスを続けているシステムでもあります。
トラブルが発生するとご迷惑をおかけするユーザが多いサービスでもあります。
そのため、とりあえず落ちずに稼働しているしということで、改善のためにインフラに大きく手を入れることには及び腰になっていました。
この数年はサービスの成長にともない現れるシステムの綻びをちょっとづつ改良しながらいこーよを支えているという状況でした。
いこーよの姉妹サービスであるいこレポでは、Railsアプリケーションを Docker コンテナで稼働させており、 コンテナ稼働環境として ElasticBeanstalk を採用しました。 それ以降のプロダクトはそれを踏襲したシステム構成で運用しています。
一方、いこーよは EC2 上で直接 Rails を稼働させる昔ながらのインフラでした。 Ruby やその他モジュールのアップデートは Docker 環境とは異なり手間が大きいのことが課題として大きくなりつつありました。
また、メールサーバや memcached サーバ、Zookeeperなど扱い方が異なるサーバ・ソフトウェアが相乗りで1つのサーバに直接インストールされていたりすることも運用を煩雑にしていました。
この状況を改善するため、昨年の秋からいこーよインフラ刷新プロジェクトとして、インフラ基盤に kubernetes を導入する準備を進めてきました。 その検討過程で考えていたこと、やったことを少し紹介します。
考えたこと
要件定義
プロジェクトを開始する前に、どのようなインフラを作りたいかについてエンジニアチームで話し合いました。
すでに問題が顕在化しているものから、それってインフラの問題? なものまで次の様な項目が数十個挙がりました(恥を偲んでいくつか披露します)。
- 繁忙期の負荷を心配しながら見守らなくてよくしたい
- リリース時にパフォーマンス低下しないようにしたい
- 長期間参照できるメトリクスを収集したい
- インフラもコード化したい
- etc
それらに優先度をつけ、やるものやらないことを決めました。
更にそれらを汎化し、一般的にインフラとして検討すべき次の観点について判断の指針を要件定義として定めました。
- 可用性
- 性能
- 運用容易性
- セキュリティ
- 開発効率
- コスト
あとから出てくる課題もこの要検定義を満たすのに必要なものはやる。
そうでないものは優先度を下げるという判断を行いました。
コンテナを何で動かす?
インフラを刷新するに当たり、どの様な形であれ Docker コンテナ上で稼働させるということは決めていました。
Dokcer コンテナを使えば、Ruby、それに必要なミドルウェアやライブラリなど Rails を動かすために必要なものがすべてがイメージに含められます。
デプロイするだけでそれらのアップデートも適用できてしまいます。
すでに Docker コンテナで稼働している他のサービスの運用でそのメンテナンス性の良さは実感できていましたし、求める運用容易性を満たすためにも必要なものでした。
アクトインディのインフラは AWS にあります。
AWS のコンテナ環境には ECS や、ECS をベースとしているElasticBeanstalk があります。
ElasticBeanstalk はすでにいこーよ以外のサービスで運用している実績があります。
ただ、次の点で満足していませんでした。
じゃあ、ECS はどうかとも考えましたが、ElasticBeanstalk で不満に思っていることの一部は ECS に起因しているものもあり決定打に欠けました。
そこで、最近事例が増えつつある Kubernetes なるものを自分もやってみたいと思い Kubernetes ありきで構成を検討し始めました3。
Kubernetes を使うにあたり、Kubernetes そのものの運用負荷はできるだけ下げたいと考え、AWS EKS を採用することにしました。
検証を進める中で、求めていた可用性、運用容易性や開発効率も実現できそうだと手応えを強めながらプロジェクトを進めていきました。
GitOps を実現する
いこーよは私が入社した当時から Github のプルリクエストをマージすれば本番環境にデプロイされるリリースプロセスの自動化がされていました。
プルリクエストをマージすると Github のリポジトリをポーリングしている Jenkins が RSpec のテストを実行して、capistrano で、EC2 にデプロイするというものです。
一方、Kubernetes の CI/CD のキーワードとして GitOps というのをよく見かけます。
GitOps とは weaveworks 社が提唱するCI/CDの考え方です。極々簡単に言うと宣言的にインフラを定義できる Kubernetes では Git リポジトリと実稼働するシステム状態を一致させるよう管理しようというものです。そうすることですべての変更が Git の履歴として管理でき、現在のシステム構成がどうなっているのかリポジトリを見ればわかるようになります。
具体的にアプリケーションとインフラの変更を稼働するシステム上にどの様に適用するのかというと、プルリクエスト上の操作を起点に CI/CD を自動化するということになります。
すでに運用としては GitOps っぽいものはすでにできていたので、この運用はそのまま残したいと思いました。
ただ、従来のリリースプロセスでは CI と CD が一体化しており、運用しづらい部分がありました。
そこで weaveworksの提唱通り CI と CD を分離し、GitOps を取り入れることにしました。
いこーよに関わるGitリポジトリを次の2つに分けました。
- アプリケーションリポジトリ
- マニフェストリポジトリ
アプリケーションリポジトリの変更を起点に CI を実行し、マニフェストリポジトリの変更を起点に CD を実行しています。 アプリケーションリポジトリの変更とはプルリクエストのマージです。コードレビュー後、各開発メンバーがマージします。 すると、Dockerイメージをビルドし、RSpec のテストを実行します。 ここまでが CI です。
そして、テストされたDockerイメージを使うようにマニフェストリポジトリのマニフェストを更新する。
すると、その通りに本番環境の Kubernetes へのデプロイが実行されるという CD の処理を実現することとしました。
これにより日々のリリースという運用の容易性と開発効率を維持できると考えました。
導入したもの
上記のようなことを考えつつ、次のような方針を軸にCI/CDも含めたいこーよの本番運用のシステム構成を検討しました。
- Kubernetes クラスターを運用する。
- 運用には GitOps を取り入れる
その上で前述の要件を満たすために今回のインフラ刷新プロジェクトでアクトインディとして新たに導入した技術要素は kubernetes 以外では次のものがあります。
- AWS CDK
- ArgoCD
- Datadog
AWS CDK
今回のインフラ刷新でもう1つ決めていたことがあります。
それは「できるだけインフラをコード化する」ということです。
AWS コンソールをポチポチいじって設定するのは、変更履歴が管理できないし、担当者任せの部分が多くなり再現性を担保できません。 なのでできる限りコンソールによる変更作業をなくしたいと考えました。
Kubernetes の中はすべて YAML のマニフェストでコード化しますが、Kubernetes だけでは CI/CD も含めた運用に必要なインフラ全ては実現できません。 第一、Kubernetes を稼働させるEKSクラスタは kubernetes では作れません。
もともとAWS謹製ということ、無理な変更は適用されずロールバックされる点で CloudFormation を信頼していました。 でも、あのYAMLは規模が大きくなっていくると管理がちょっと大変だなぁとも思っていました。 それなら、Teraformってどうだろうか?そう考えていたところに、ちょうどいいタイミングで AWS CDK が GA となりました。 試してみると、YAMLとは違って、次の点で実装しやすいと感じました。
- クラスやメソッドを使って見通しよく分割できる
- 通常のプログラミングと同じ手法でテストも可能
- それでいて最終的に CloudFormation のスタックとしてデプロイできる
いくつか習作も作ってみた上で CDKを採用しました4。
CDKでは次を構築しました。
- EKS クラスタ
- EKS クラスタで利用する IAM Role
- CI で使う CodePipeline や CodeBuild
- ECR レジストリなど
DockerイメージのビルドCIなどは設定ファイルにソースリポジトリを追加する程度で新設できるようになりました。
CDKのコードは cdk deploy コマンドでデプロイできます。
しかし、それをローカル環境から実行してしまうと環境差異がでる恐れがあるので、本番環境へは CodeBuild でcdk deploy コマンドを実行するようにしています。
CDK のリポジトリでプルリクエストをマージすると自動的に実行される様にして、インフラ変更の CD の自動化も実現しました。
もちろん、CDK をデプロイする CodeBuild の構築も CDK で行います。そしてそのデプロイも CodeBuild です。
ちなみに、CDKでは実装言語をいくつか選べますが TypeScript を使っています。
VS Code だと関数定義などがポップアップで表示されるため引数の定義を調べる手間が少ないですし、何より型が強力でコードの間違いを検出しやすいのでおすすめです。
ESLintでコードの書き方もある程度統一したルールを強制できます。
ArgoCD
GitOps を実現するに当たり、どうやって Kubernetes にデプロイするのか? Flux、 Jenkins X などの候補がありましたが、ArgoCDを採用しました。
ArgoCDは GitOps のためのCDツールであると謳っている OSS です。
マニフェストのリポジトリとディレクトリを登録すると、そこに変更があったときに自動的に Kubernetes に適用してくれます。
採用の決め手は次のとおりです。
- インストールが比較的簡単
- ドキュメントがわかりやすい
- Github アカウントを使った認証がある
- GUI がある
インストールは ArgoCD のリポジトリにあるマニフェストで特につまるところなくできました。
Github アプリとして連携させると Github アカウントでログイン可能となります。
Github のオーガニゼーションでどのチームに属しているかによって付与する権限の変更も可能となっているところも使い勝手がいいです。
そして GUI があることが大きかったです。
Kubernetes のマニフェストを編集するのは一部の開発メンバーですが、アクトインディではリリース作業はデザイナーも含めコードを変更するメンバー全員が行う日常的な作業です。
デプロイの進行状況などが確認できる GUI があったほうがそれほど詳しくないメンバーにもわかりやすい。
自分で状況を確認する場合にも便利です。
実際に運用してみて次の機能も便利で、改めて導入してよかったと思いました。
- 各コンテナの標準出力が GUI で確認できる
- コンテナのログをさっと確認するのにとても便利です。
- デプロイの PreSync, PostSync で実行されるJob
- DBのマイグレーションをデプロイ前に実行したり、デプロイ完了をSlackに通知するのに便利です。
ArdoCD を組み込んで最終的に、CI/CD は次のように構築しました。
- CI
- Github でプルリクエストをマージするとCodePipeline + CodeBuild で Docker イメージのビルドとテストを実行
- テストが通るとマニフェストリポジトリに自動でプルリクエストを作成して Kubernetes のマニフェストを更新、自動的にマージ
- CD
- マニフェストの変更を ArgoCD が検知。Kubenetes に適用し本番環境にデプロイ
CI の最後で CD をトリガーしているところが CI と CD を分離しきれてないといえばそうでしょう。しかし、多いときには1日10回程度リリースするのでそこは自動化しておかないと手間がかかってしょうがないというところです。
Datadog
システムのモニタリングには AWS の CloudWatch を使ってきましたが、kubernetes 導入とともに Datadog も導入しました。
Cloudwatch は便利だと思うのですが、不満に思うこともいくつかありもっと便利なツールはないかと思っていました。
かと言って、Prometheus を導入してその運用もというのはちょっとしんどい。
というようなことを勉強会か何かでたまたま出会った人に話してみました。
その人は Prometheus の同人誌を作っているような人だったのですが、「だったら Datadog いいですよ!」とのことだったので検討し始めました。
評価してみて、次の点がよいと思い導入を決めました5。
- Kubernetes 内のリソースのモニタリングが便利
- 自動的に作られる Kubernetes ダッシュボードが独自ダッシュボードを作る際に非常に参考になりました
- メトリクスが探しやすい
- リソースを特定して、そのメトリクスを選択していく Cloudwatch に比べ、メトリクスを選んでから対象リソースを絞り込む方式が使いやすかった
- Slack や AWS SNS への通知が簡単
- Note 機能が便利
- あれ? と思ったメトリクスの動きにメモを付けて残しておけます
- データが丸められない
特に最後のデータが丸められないというは重要でした。Webサービスを運用していると急なアクセス急増、いわゆるスパイクが発生することがあります。
発生直後はメトリクスグラフで鋭いピークが確認できますが、時間が経つと30分平均の値に丸められたりして、その時システムがどうなっていたのか調べきれなくなります。
Datadog だと長い期間のグラフでは表示上は丸められるものの、期間を絞り込んでいくと詳細なメトリクスが参照できます。
そのおかげであのときどうなってたんだろう? ということを時間が経っても調べられます。
ただ、ALBやRDSなどのAWS のマネージドサービスを監視するにはやはり Cloudwatach が必要な部分もあり併用しています。
移行に際して
構築、機能検証をしながら、本番のいこーよを動かす構成を作っていきました。 それができたら負荷試験、パフォーマンス試験を行い、運用を想定して障害時の対応についても検証しました。
上記に加えて、移行までに特にやっておこうと思ったのは EKS のマネージドノードグループや、EKS クラスタそのもののリプレース手順を確立しておくということでした。
Kubernetes もまだまだ多分に発展途上のプロダクトですし、インフラを構築するのに使っている CDK も高頻度で更新が続いているツールです。
この先、単純にはアップデートはできず、まるごと入れ替えるしかない局面がきっとあるだろうと考えています。
そのときにサービスを止めずにリプレースしていければ躊躇せずアップデートしていけるだろうと思いました。
その手順のためにシステム構成を見直したり、CDK の実装をリファクタリングしたりといった調整を行いました。
今週、クラスターのインスタンスタイプの変更を行うためにノードグループの入れ替えを行いましたが、これらの準備のおかけで慎重に、しかし恐れることなく作業できました。
最後に
ちょっととりとめないエントリになりましたが、いこーよのインフラの再構築に際して考えたこと、 これまでの取り組みを整理しておこうと思い書いてみました。 なにかの参考になれば幸いです。