morishitaです。
先日、Rubocop Performance の速度比較について3回に分けて書きました。
どんな言語でも多かれ少なかれあることですが、Rubyでも同じ結果を得るのに複数の実装方法があり、読みやすさ、わかりやすさ、文字数・行数の多少、実行速度などの点でそれぞれ良し悪しがあるなぁ。とやってみて改めて思いました。
メンテナンス性の観点からは書きやすい、読みやすい、わかりやすいコードを書けばいいと思います。
ただ、ユーザにとってより良いサービスの提供を考えると速さは正義、ちょっとでも速い実装方法を選択したいものです。
で、上記のエントリを書きながら、これとこれはどっちが速いんだろうと思ったいくつかを計測してみました。
計測について
計測には BenchmarkDriver を利用しました。
計測コードでは文字列、配列、ハッシュなどは定数にして使い回すようにしています。
論点にしているポイントだけをなるべく計測するため、これらの生成コストを計測に含めないようにするためです。
単に比較対象同士を計測するだけでなく複数のRubyのバージョンで計測しています。
一応、Rubocopのときと同様、次のRubyバージョンで計測しました。
- 2.3.8
- 2.4.6
- 2.5.4
- 2.6.3
- 2.7.0-preview1
結果は秒あたりの実行回数 ips (Iteration per second = i/s)で示します。
各結果ともbenchmark_driver-output-gruffによるグラフで示しますが、グラフが長いほうが高速ということです。
また、結果の値自体は計測環境の性能により変わります。
なので、サンプル間の差に着目してください。
では順に見ていきます。
String#tr関連
String#trってあんまり使ったことなかったのですが、使い方によっては文字種の変換などできるので面白いなと思って。
全角 −> 半角変換 NKF vs String#tr
まずは全角英字を半角に変換する処理。
ユーザ入力の正規化などで使う場面もあるかと。
NKF を使う場合と比べてみました。
計測コードは次のとおりです。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY require 'nkf' NKF_OPTS = '-Z1 -w -W' HANKAKU = 'a-z' ZENKAKU = 'a-z' STR = 'abcdefghijklmnopqrstuvwxyz' def use_nkf NKF.nkf(NKF_OPTS, STR) end def use_tr STR.tr(ZENKAKU, HANKAKU) end RUBY x.report %{ use_nkf } x.report %{ use_tr } end
で結果が次の通り。

あーやっぱ NKF の方が速いですね。
こんな処理用のツールですし。
小文字 −> 大文字変換 String#upcase vs String#tr
続いて、英字の小文字−>大文字変換。
String#upcase と比べてみました。
計測コードは次の通り。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY STR = 'abcdefghijklmnopqrstuvwxyz' AZ_DOWN = 'a-z' AZ_UP = 'A-Z' def use_upcase STR.upcase end def use_tr STR.tr(AZ_DOWN, AZ_UP) end RUBY x.report %{ use_upcase } x.report %{ use_tr } end
結果は次の様になりました。

String#upcaseの方が圧倒的に速いですね。
まー、素直に専用メソッド使いましょう。
String#trでもできるんだけど、専用メソッドなりクラスがあるならそっちがやったほうがいいですね。何したいかも明確になるでしょうし。
ループ .times.map vs range.map
times と Range、決まった回数繰り返すどちらもよく使われるかなと思います。
どちらが速いかをmap を使って配列を生成する次のコードで比較しました。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def use_times 100.times.map{ |i| i } end def use_range (0...100).map{ |i| i } end RUBY x.report %{ use_times } x.report %{ use_range } end
結果は次のとおりですが、Rangeの方が僅かに速いですかね。

文字列連結
文字列の連結の方法はいくつかありますが、次を比較しました。
String#+StringIOString#<<String#concat[String].join
計測コードは次のとおりです。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY STR = %w( あ い う え お か き く け こ さ し す せ そ た ち つ て と な に ぬ ね の は ひ ふ へ ほ ま み む め も や ゆ よ ) def string_plus s = '' STR.each do |str| s += str end s end def string_io s = StringIO.new STR.each do |str| s.write str end s.string end def string_push s = '' STR.each do |str| s << str end s end def string_concat s = '' STR.each do |str| s.concat str end s end def string_array_join s = [] STR.each do |str| s.push str end s.join end RUBY x.report %{ string_plus } x.report %{ string_io } x.report %{ string_push } x.report %{ string_concat } x.report %{ string_array_join } end
結果は次の様になりました。

最速は String#<< ですね。
String#<< と String#concat って同じと思っていたのに差があるのかぁ。
&:メソッド と ブロック
Array#map(&:to_s)の様に省略するのとブロックを渡して処理する書き方があると思います。
結果は同じでも速度差があるのか次のコードで計測してみました。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY RANGE = (1..100) def use_amp RANGE.map(&:to_s) end def use_block RANGE.map{ |i| i.to_s } end RUBY x.report %{ use_amp } x.report %{ use_block } end
結果は次のとおりです。

結果は省略する書き方の方が少し速いですね。
見た目も簡潔だし、省略していきましょう。
バージョン間の速度の違い
バージョンによっても速度の違いが大きいものがあるなとRubocopのときも思いました。
実装方法間ではなくバージョン間の速度差を見てみます。
リテラル生成
プログラム中でよく作成する次の3つのリテラル生成の速度を比べます。
StringArrayHash
Rubocop Performanceを測ってみた。後編のおまけでも紹介したのですが、1つのグラフに入れて差がわかりにくくなってしまったので、個別にグラフを作成しました。
String
まずはストリング。 次のコードで計測しました。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def string_literal 'string literal' end RUBY x.report %{ string_literal } end
結果は次の通り。

あれ? なんか緩やかに遅くなってるような…。
Ruby 2.7はこれから最適化されるのかな。
Array
続いて配列です。
次のコードで計測しました。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def array_literal [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] end RUBY x.report %{ array_literal } end
結果は次のとおりです。
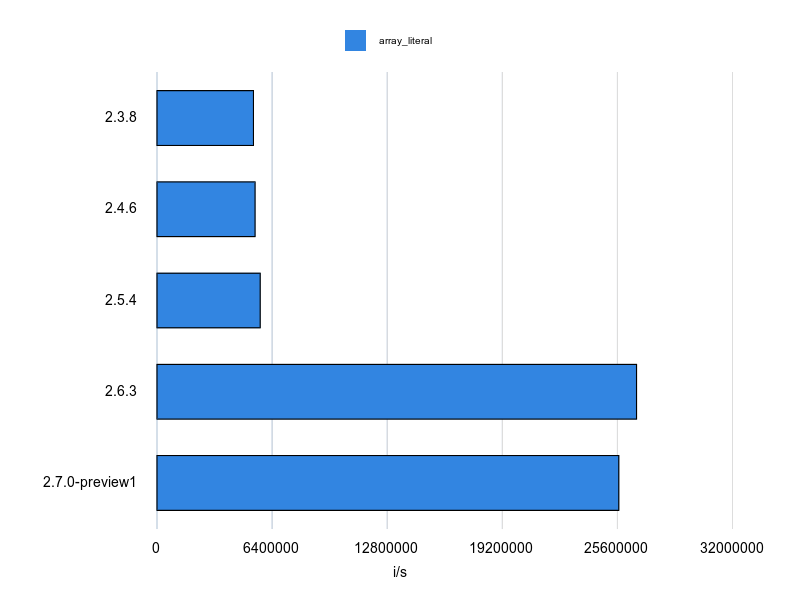
Ruby 2.6 で劇的に速度アップしています。 Ruby 2.5以下を使っているならさっさとアップデートしたほうが良いですね。
Hash
最後はハッシュです。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY def hash_literal { a: 1, b: 2, c: 3, d: 4, e: 5, f: 6, g: 7, h: 8, i: 9, j: 0 } end RUBY x.report %{ hash_literal } end
結果は次の通り。

バージョンが大きいほど速くなってますね。
Splat展開
Splat展開とはメソッド引数とかで配列の前に*をつけて要素を展開するやつですね。
配列を展開してまた同じ配列を作るなんて、実用性皆無なコードですが次のコードで計測しました。
require 'benchmark_driver' output = :gruff versions = ['2.3.8', '2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1'] Benchmark.driver(output: output) do |x| x.rbenv *versions x.prelude <<~RUBY STR = %w( あ い う え お か き く け こ さ し す せ そ た ち つ て と な に ぬ ね の は ひ ふ へ ほ ま み む め も や ゆ よ ) def splat [*STR] end RUBY x.report %{ splat } end
結果は次の通り。

これも Ruby 2.6で大幅に速くなっています。
まとめ
書き方一つで結構差がつくのが面白いですね。 小さなプログラムでは気にしなくていいかもしれませんが、Webアプリケーションは多くのリスクエスト並列で処理するので、速いコードを心がけたいものです。
あと、Rubyは最新バージョンを使うほうが速度面でもメリット大きいですね。
最後に
アクトインディではエンジニアを募集しています。 actindi.net