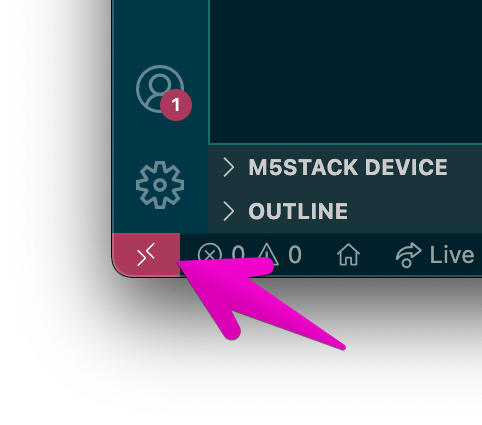
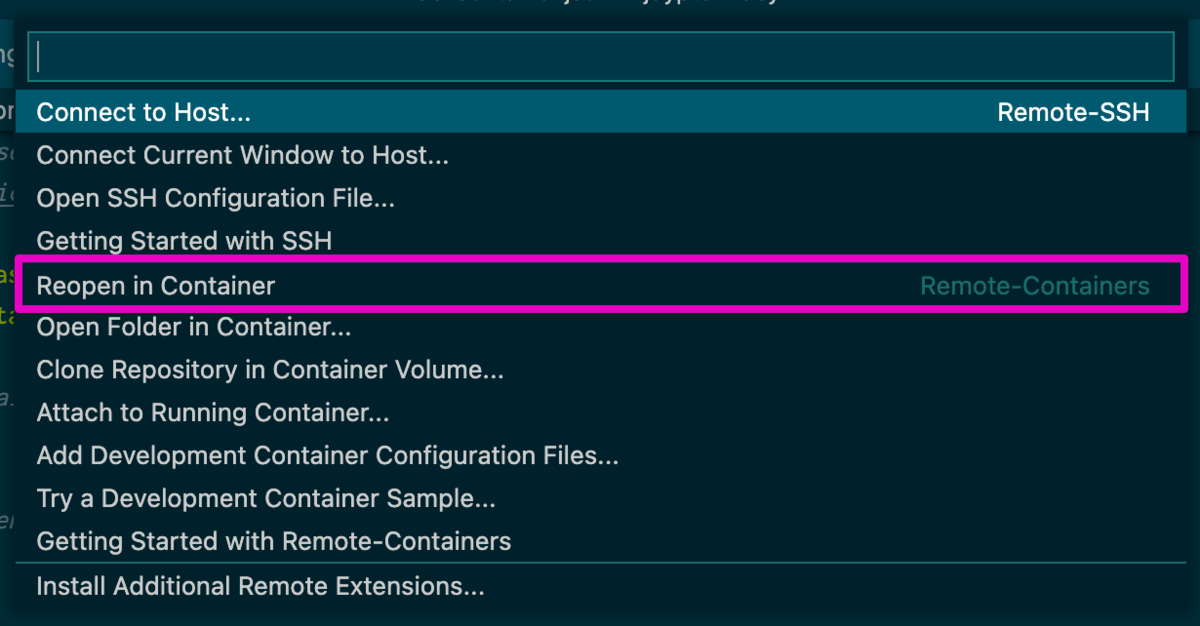
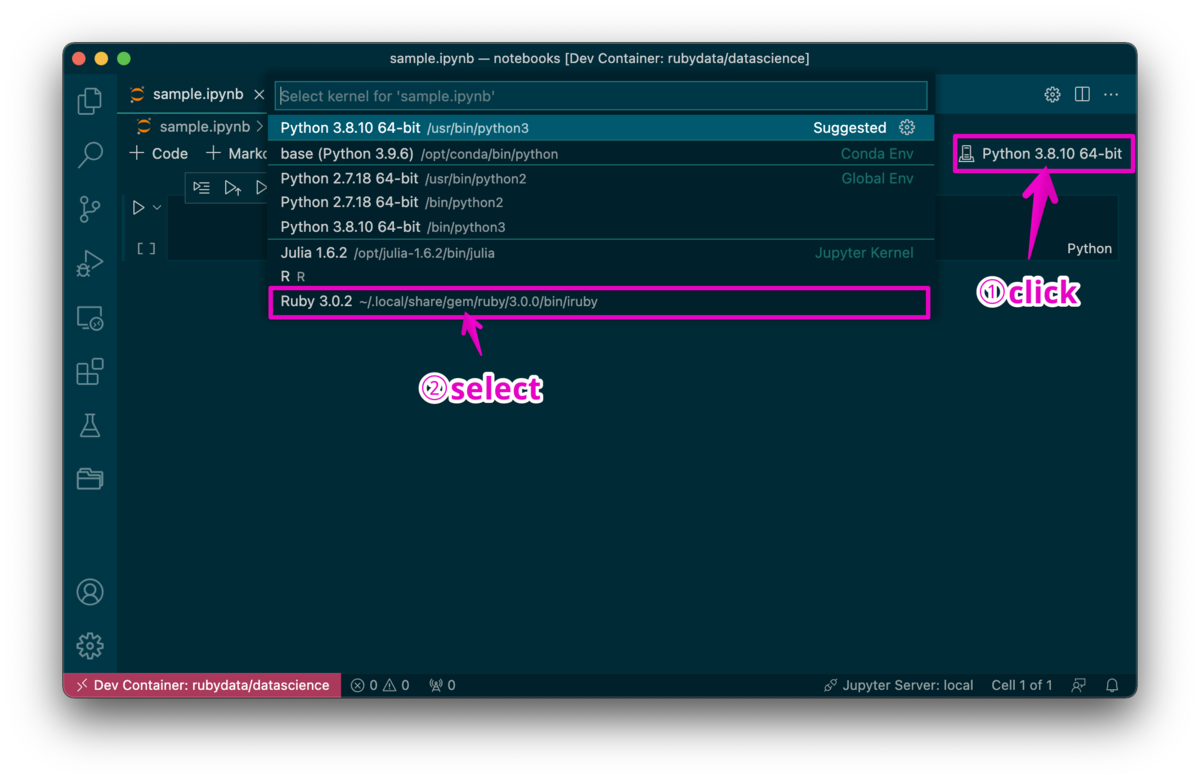
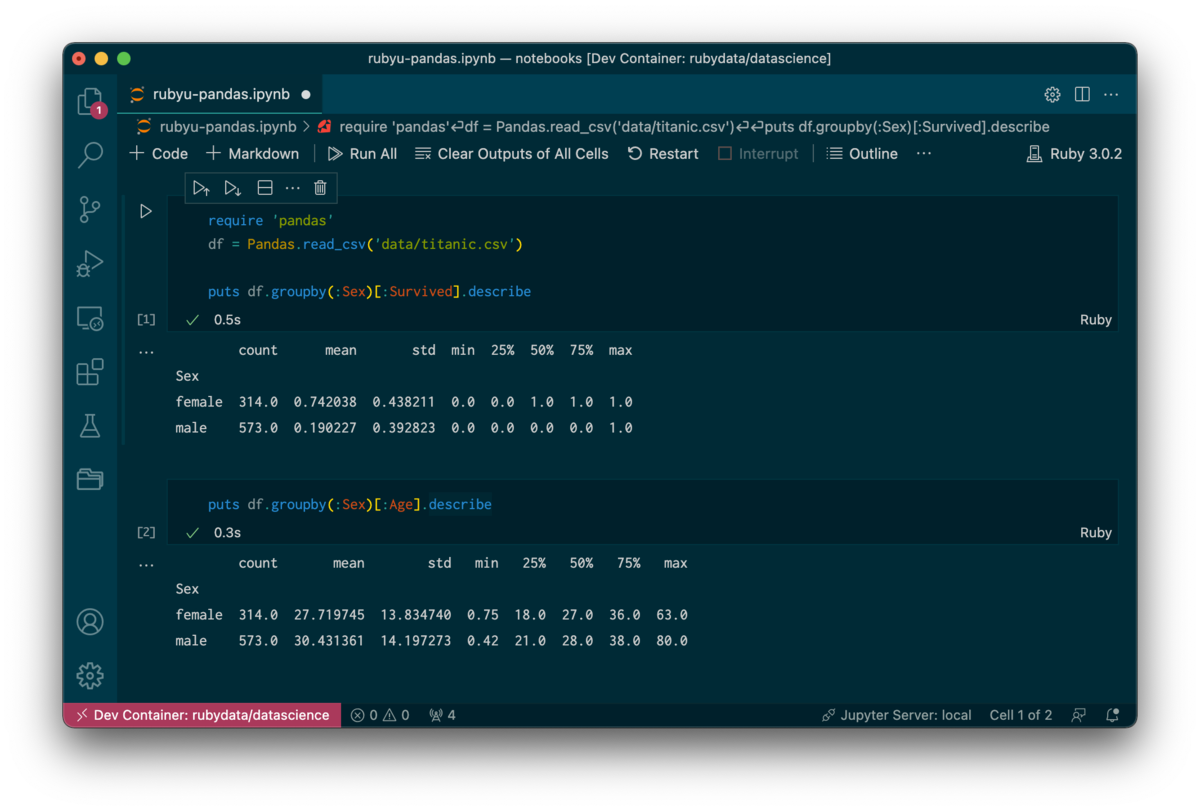
// For format details, see https://aka.ms/devcontainer.json. For config options, see the README at:// https://github.com/microsoft/vscode-dev-containers/tree/v0.205.2/containers/ruby{
"name": "rubydata/datascience",
"image": "rubydata/datascience-notebook:latest",
// Set *default* container specific settings.json values on container create.
"settings": {},
// Add the IDs of extensions you want installed when the container is created.
"extensions": [
"rebornix.Ruby",
"ms-python.python",
"ms-python.vscode-pylance",
"ms-toolsai.jupyter",
"ms-toolsai.jupyter-keymap",
"julialang.language",
"Ikuyadeu.r"
],
"mounts": [
"type=bind,src=${localWorkspaceFolder}/notebooks,dst=/notebooks"
],
"workspaceFolder": "/notebooks",
"initializeCommand": "mkdir -p notebooks"
}
モダンな API では application/json なレスポンスを返すものがほとんどでしょう。
VCR はなにも設定しなければ API のレスポンスをそのまま保存します。
殆どの API はサイズを減らすため改行やスペース、インデントが省かれているので見やすい JSON 形式ではありません。
改行やインデントを入れて見やすい形式で保存するには次のようなコードを設定に追加します。
config.before_record do |interaction|
interaction.response.body.force_encoding 'UTF-8'
response_content_type = interaction.response.headers['Content-Type'].first
if response_content_type.include?('application/json')
interaction.response.body = JSON.pretty_generate(JSON.parse(interaction.response.body))
endend
API の仕様で秘密情報が格納されているヘッダなどの場所は決まっているはずです。なのでその場所をピンポイントで置換する実装も可能です。しかし、その場合 API のヘッダーや Cookie の仕様まで知っている必要があるでしょう。
長時間変わらないセッション ID や、計算で算出する動的なトークンが格納されている場合には、リクエスト・レスポンスの構造を調べてマスクする必要があるでしょう1。
しかし、固定のトークンで認証する API は多く、それらを利用するプロダクションコードでも環境変数などで渡すことが多いと思います。ならばその環境変数の値をとにかく置換するようにしたほうが API の詳細を知らなくても良くて手っ取り早く、 API の仕様が変わっても影響されずに確実にマスクできるのでおすすめです。
リクエストで送信する値やアクセス先のリソースの状態によりリクエスト・レスポンスの構造が変わるような API があります。構造が変わると言っても値がなければキーがなくなるなどですが、存在しないキーの値に操作しようとするとエラーになりますし、キーはあっても null 値でもエラーになります。
そのように存在したりしなかったりする API の部分を掴んでいじるようなコードを VCR の設定に実装すると、エラーになったりならなかったりしてハマりがちです。でも、なにが起こっているのかわかれば解決できるでしょう。
まとめ
このエントリで紹介した設定を全部含む設定全体は次のようになります。
VCR.configure do |config|
config.debug_logger = File.open('vcr-debug.log', 'w') # for debugging
config.cassette_library_dir = 'spec/vcr'
config.hook_into :webmock
config.configure_rspec_metadata!
config.allow_http_connections_when_no_cassette = true
config.default_cassette_options = {
record: :new_episodes,
match_requests_on: %i[method path query body_as_json],
}
ifENV['ACCESS_TOKEN']
masked_token = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
config.filter_sensitive_data(masked_token) { ENV['ACCESS_TOKEN'] }
end
config.before_record do |interaction|
interaction.request.body.force_encoding 'UTF-8'
request_content_type = interaction.request.headers['Content-Type'].first
if request_content_type == 'application/json' && !interaction.request.body.empty?
interaction.request.body = JSON.pretty_generate(JSON.parse(interaction.request.body))
end
interaction.response.body.force_encoding 'UTF-8'
response_content_type = interaction.response.headers['Content-Type'].first
if response_content_type.include?('application/json')
interaction.response.body = JSON.pretty_generate(JSON.parse(interaction.response.body))
endendend
そのような動的なトークンはおそらく認証 API などで取得するか、固定の文字列(アカウント ID など)を種にして計算するものでは思われます。認証 API にアクセスする場合にはパスワード等を送信することになると思うので、それも秘密情報になりますし、取得したトークンの有効期限がながければリポジトリに入れるのは心配です。計算で求めるものは算出ロジックは公開されていると思うので計算例が多ければ種がバレる可能性もあると思われます。↩
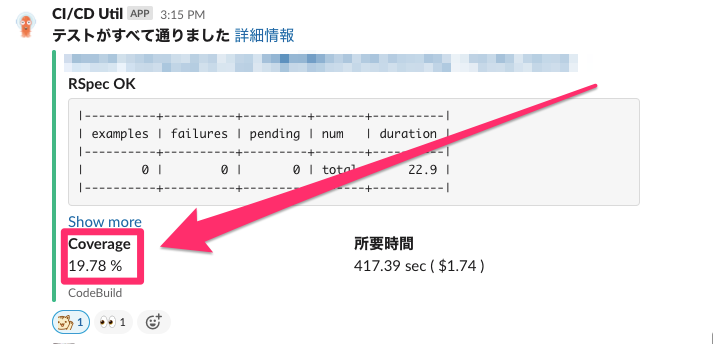
An error occurred while loading ./spec/controllers/xxx/xxx/xxx_controller_spec.rb.
Failure/Error: ActiveRecord::Migration.maintain_test_schema!
ActiveRecord::PendingMigrationError:
Migrations are pending. To resolve this issue, run:
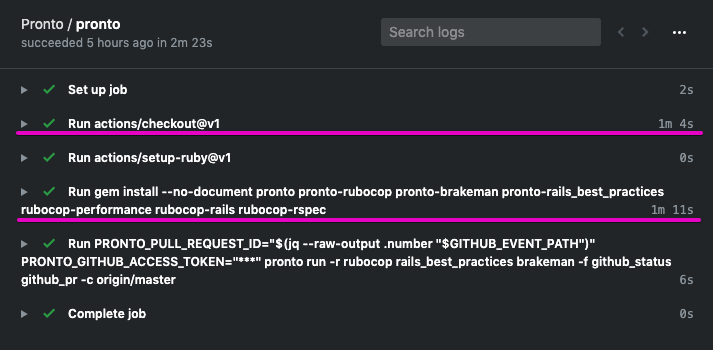
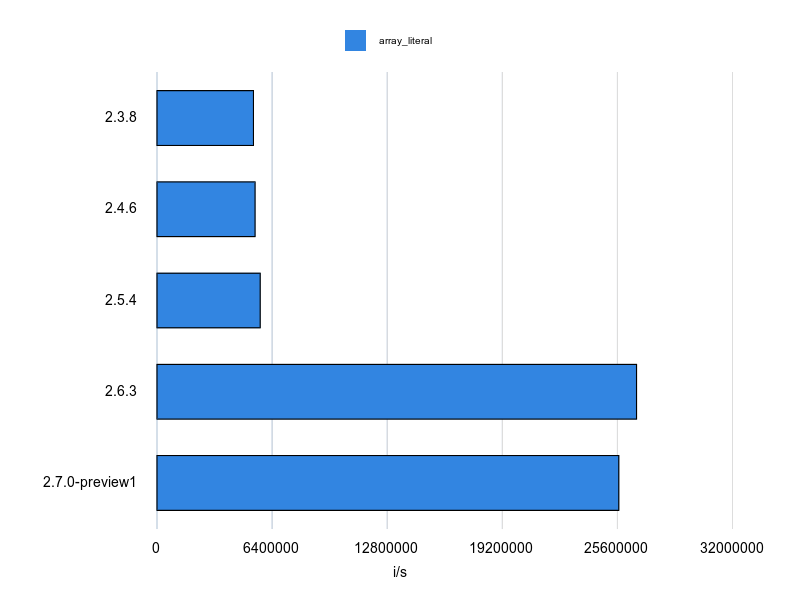
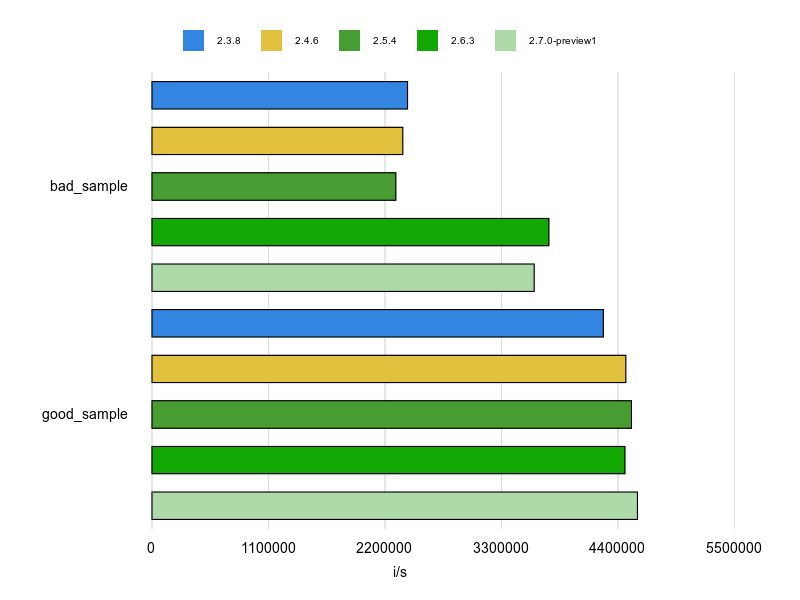
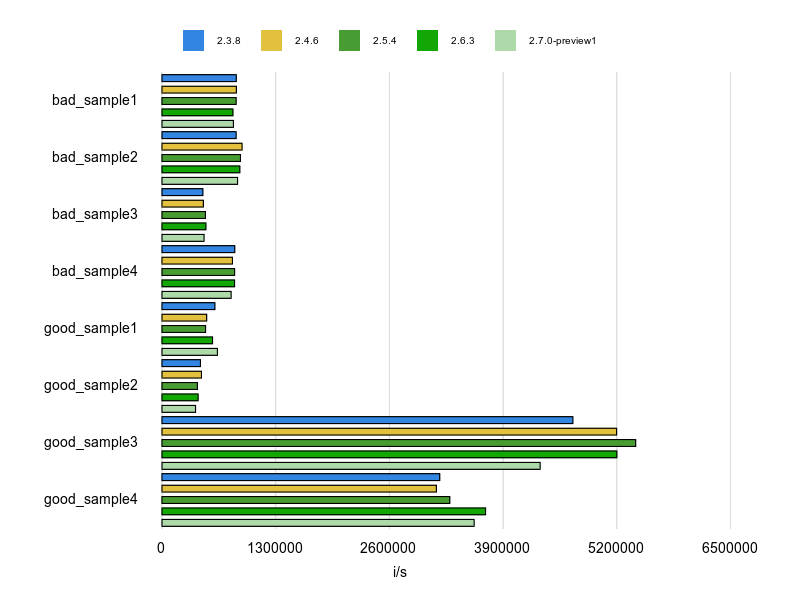
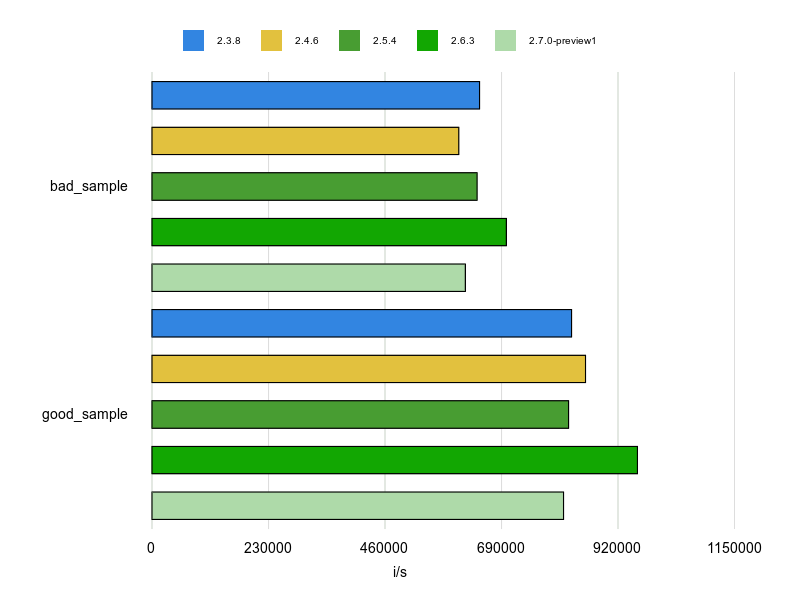
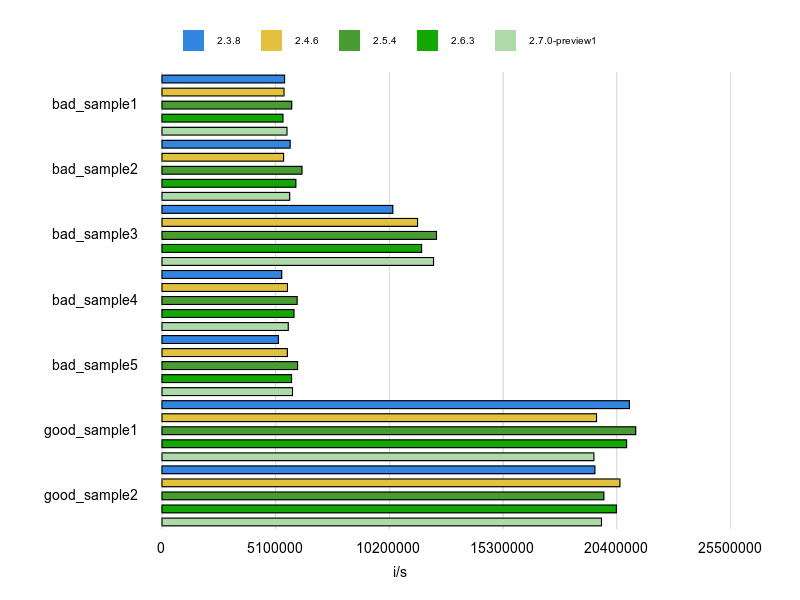
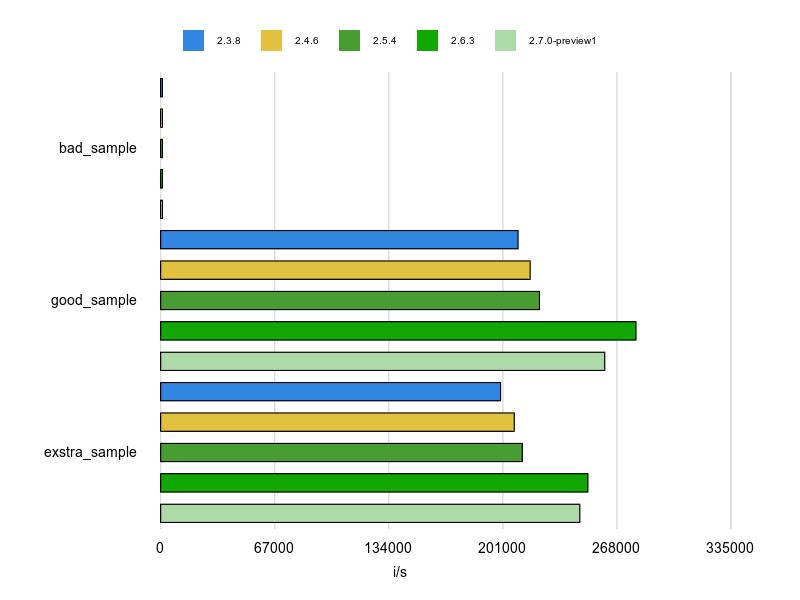
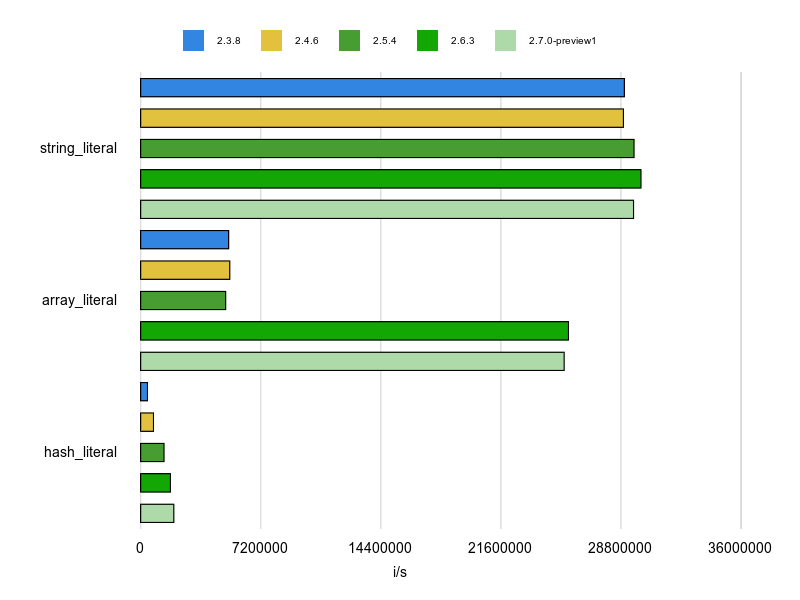
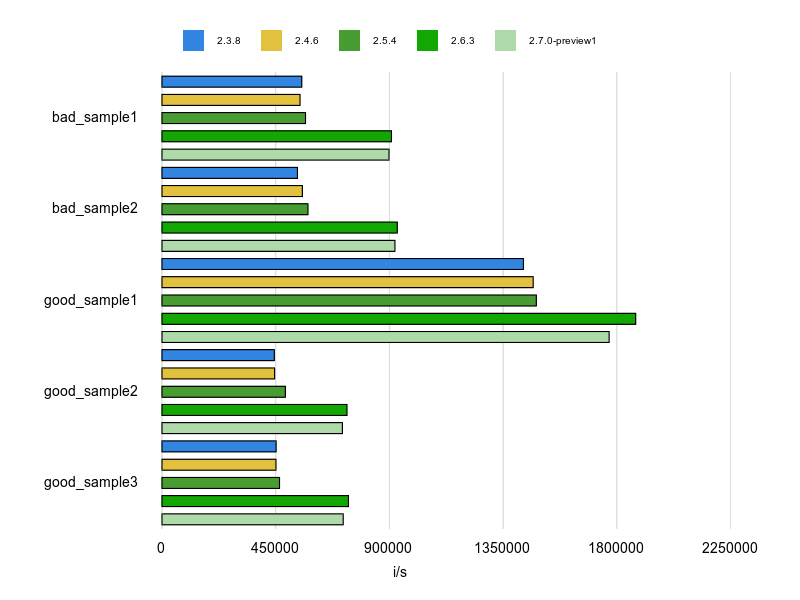
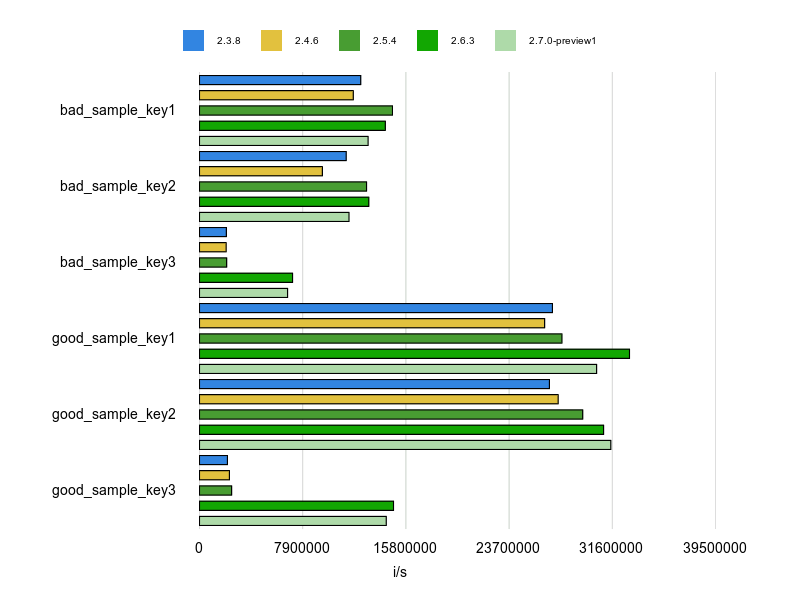
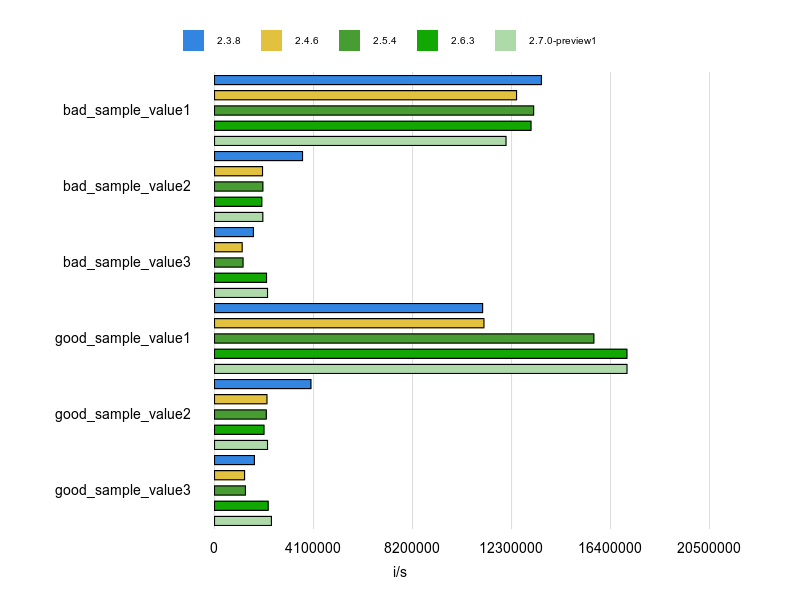
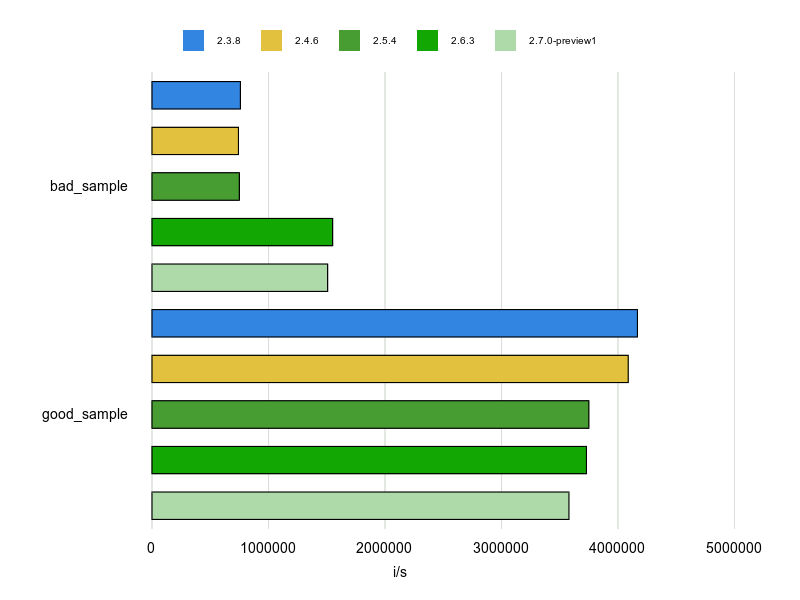
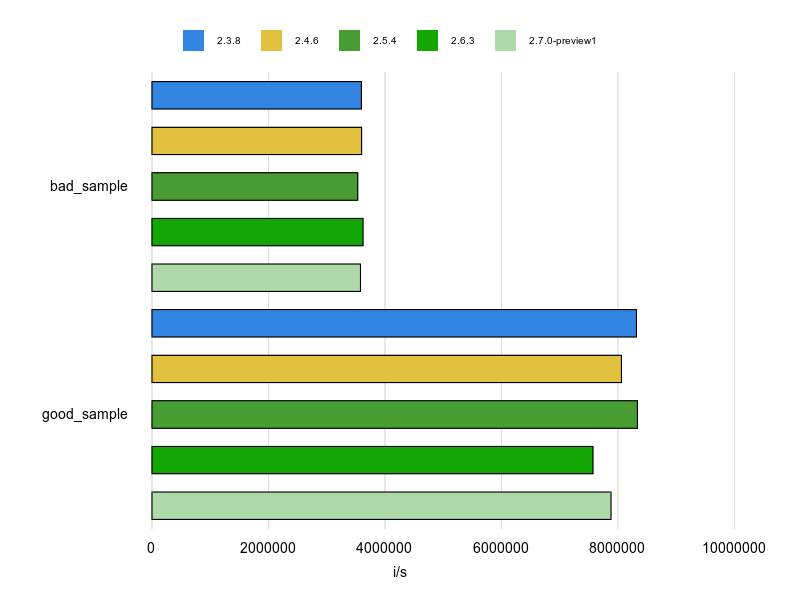
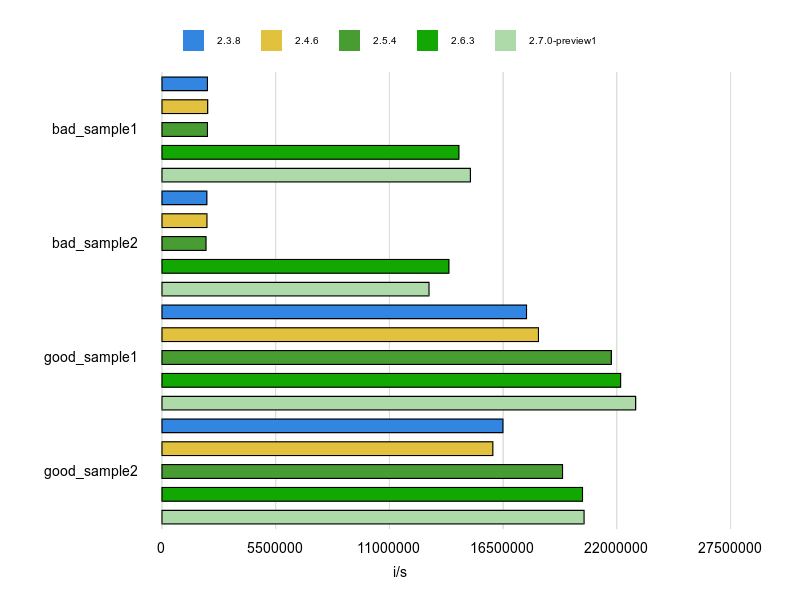
Rubocopのドキュメントに bad と good の例が掲載されていますが、基本的にはそれをBenchmarkDriverで計測してみて比較しました。
例をなるべく変更せずに計測する方針で行いましたが、文字列、配列、ハッシュなどは定数にして使い回すようにしています。
各 Cop が論点にしているポイントだけをなるべく計測するため、これらの生成コストを計測に含めないようにするためです。
# rubocop-performance Performance/RegexpMatchrequire'benchmark_driver'
output = :gruff
versions = ['2.4.6', '2.5.4', '2.6.3', '2.7.0-preview1']
Benchmark.driver(output: output) do |x|
x.rbenv *versions
x.prelude <<~RUBY def do_something(arg = nil) 1 + 1 end X = 'regex-match' RE = /re/ def bad_sample1 if X =~ RE do_something end end def bad_sample2 if X !~ RE do_something end end def bad_sample3 if X.match(RE) do_something end end def bad_sample4 if RE === X do_something end end def good_sample1 if X.match?(RE) do_something end end def good_sample2 if !X.match?(RE) do_something end end def good_sample3 if X =~ RE do_something(Regexp.last_match) end end def good_sample4 if X.match(RE) do_something($~) end end def good_sample5 if RE === X do_something($~) end endRUBY
x.report %{ bad_sample1 }
x.report %{ bad_sample2 }
x.report %{ bad_sample3 }
x.report %{ bad_sample4 }
x.report %{ good_sample1 }
x.report %{ good_sample2 }
x.report %{ good_sample3 }
x.report %{ good_sample4 }
x.report %{ good_sample5 }end
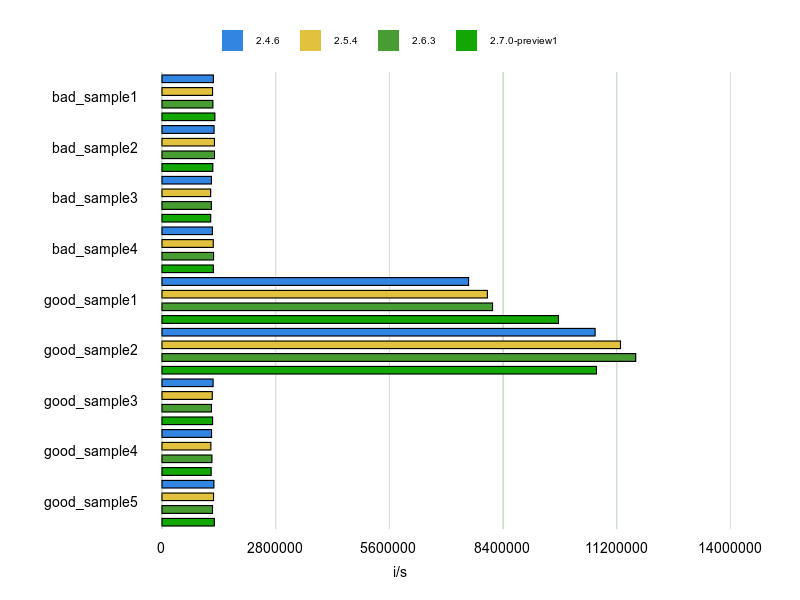
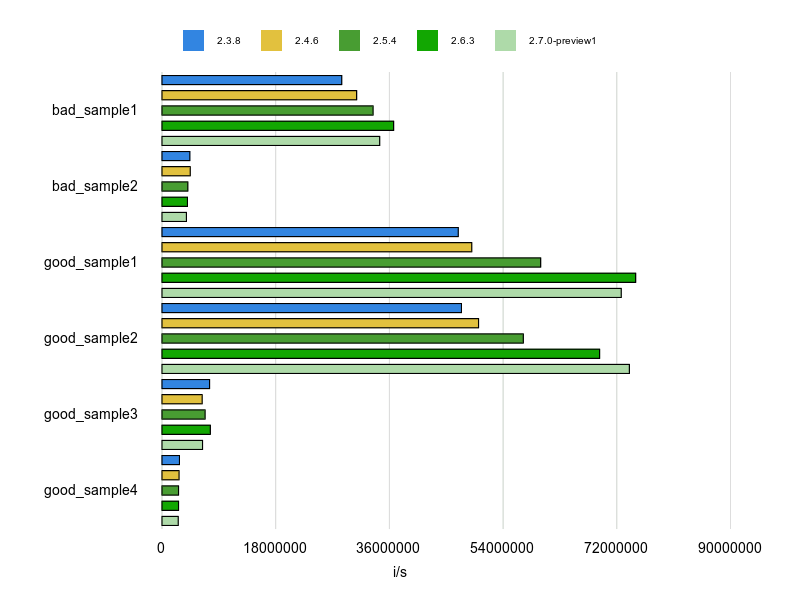
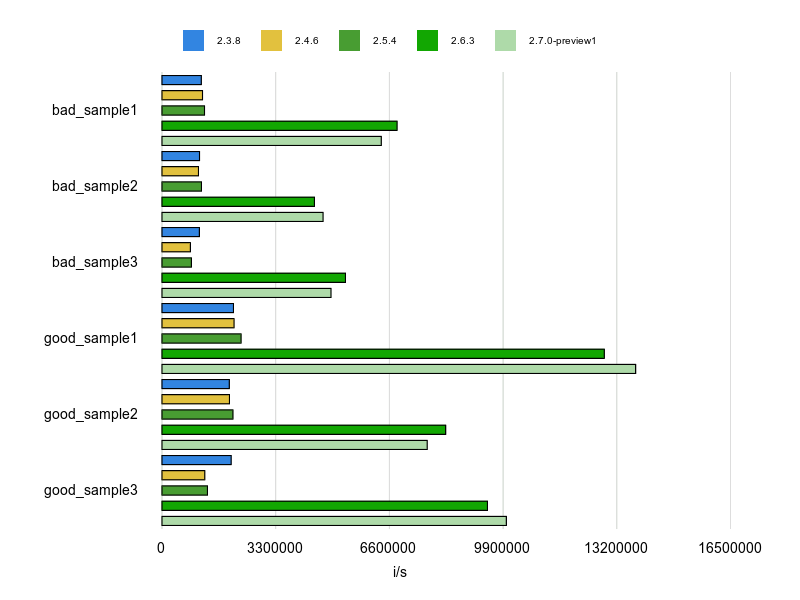
Rubocopのドキュメントに bad と good の例が掲載されていますが、基本的にはそれをBenchmarkDriverで計測してみて比較しました。
例をなるべく変更せずに計測する方針で行いましたが、文字列、配列、ハッシュなどは定数にして使い回すようにしています。
各 Cop が論点にしているポイントだけをなるべく計測するため、これらの生成コストを計測に含めないようにするためです。